The U.S. Department of Justice has released several new trial exhibits – including internal Google presentations, documents and emails related to ranking.
Here are seven that specifically discuss elements of Google Search ranking:
1. Life of a Click (user-interaction)
This is a heavily redacted PowerPoint presentation put together by Google’s Eric Lehman – and like most of the other documents, it lacks the full context accompanying it.
However, what’s here is interesting for all SEOs.
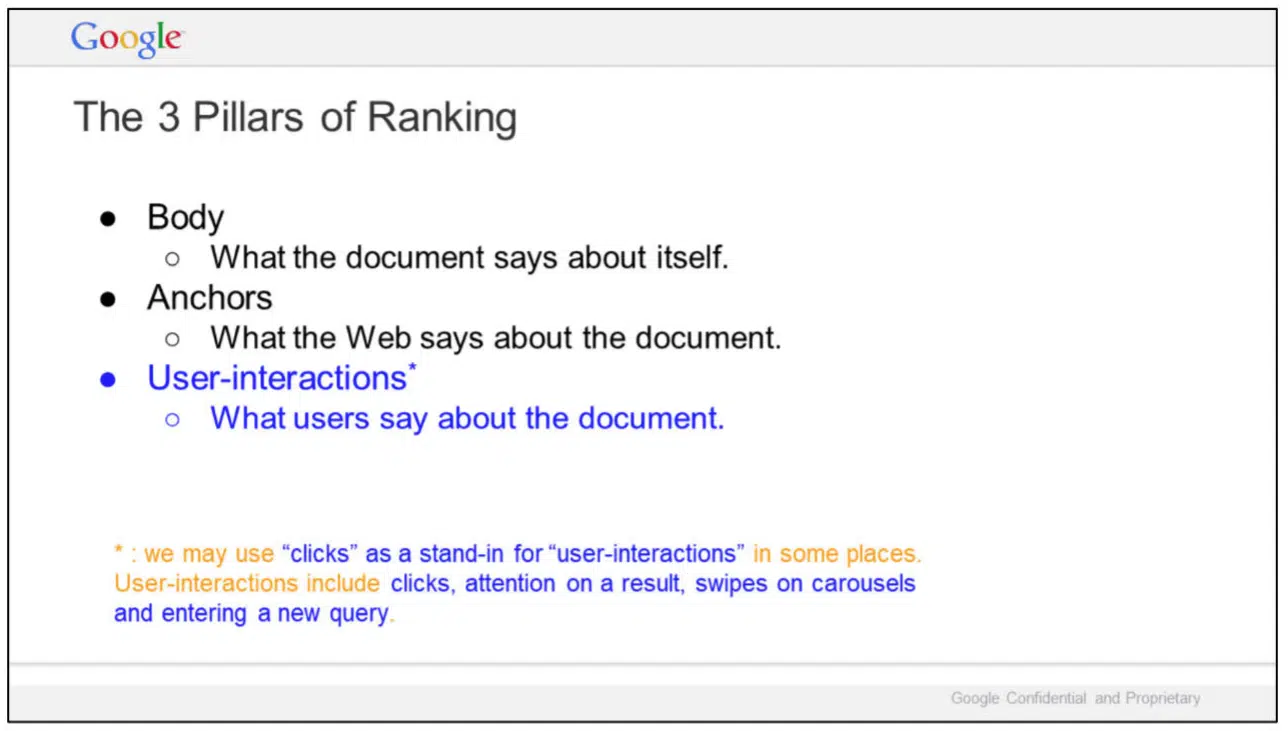
In “The 3 Pillars of Ranking,” slide, Google highlights three areas:
- Body: What the document says about itself.
- Anchors: What the Web says about the document.
- User-interactions: What users say about the document.
Google added a note about user interactions:
- “we may use ‘clicks’ as a stand-in for ‘user-interactions’ in some places. User-interactions include clicks, attention on a result, swipes on carousels and entering a new query.
If this sounds familiar to you, it should. Mike Grehan has written and spoken extensively about this for 20 years – including his Search Engine Land article The origins of E-A-T: Page content, hyperlink analysis and usage data.
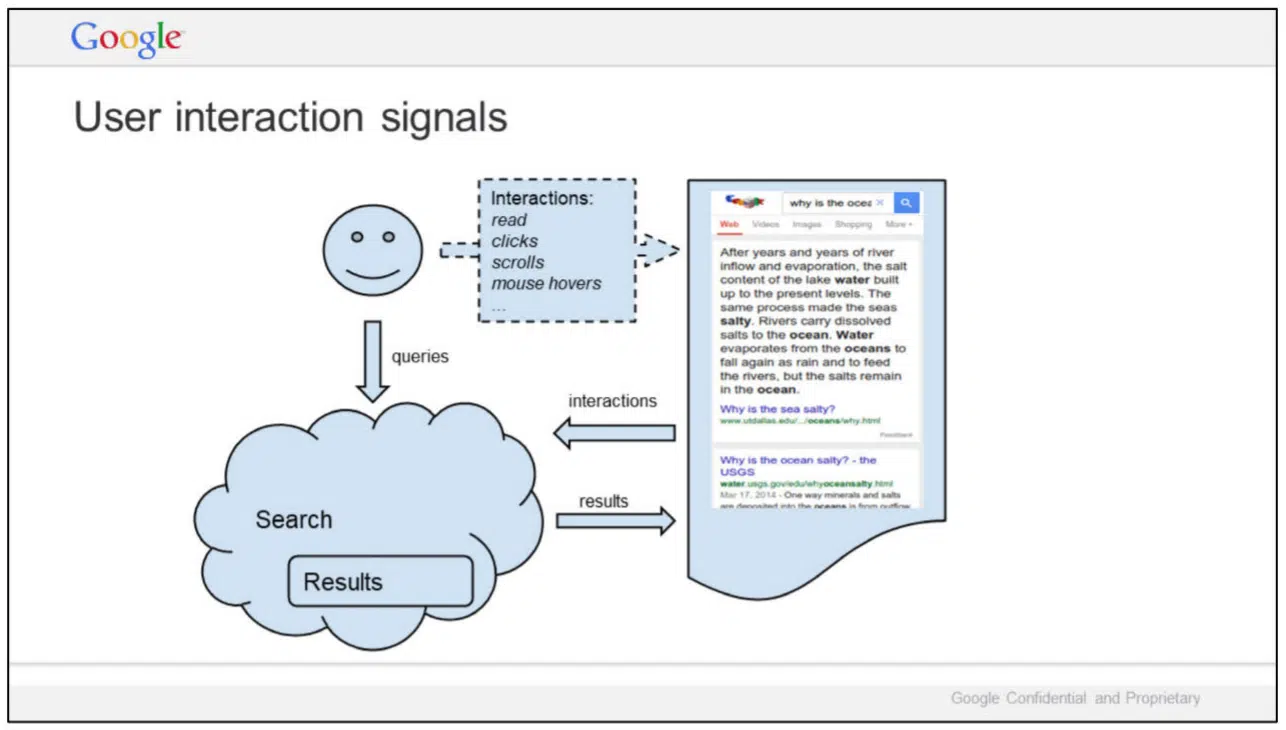
In this slide, titled “User interaction signals,” Google illustrates the relationships of queries, interactions and Search results, alongside results for the query [why is the ocean salty]. Specific interactions mentioned by Google:
- Read
- Clicks
- Scrolls
- Mouse hovers
In September, Lehman testified during the antitrust trial that Google uses clicks in rankings. However, once again, it’s important to make clear that individual clicks alone are a noisy signal for ranking (more on that in Ranking for Research). Google has publicly said it uses click data for training, evaluation, controlled experiments and personalization.
What is redacted:
- A slide titled “Metrics” – all that is visible is one line: “Web Ranking Components.”
- Seven additional slides, including two titled “Outline” and “Summary.”
Link: Google presentation: Life of a Click (user-interaction) (May 15, 2017) (PDF)
2. Ranking
These seven slides were part of a larger Q4 2016 Search All Hands presentation, prepared by Lehman.

In this slide, Google says “We do not understand documents. We fake it.”
- “Today, our ability to understand documents directly is minimal.
- So we watch how people react to documents and memorize their responses.”
And the source of Google’s “magic” is revealed:
“Let’s start with some background..
A billion times a day, people ask us to find documents relevant to a query.
What’s crazy is that we don’t actually understand documents. Beyond some basic stuff, we hardly look at documents. We look at people.
If a document gets a positive reaction, we figure it is good. If the reaction is negative, it is probably bad.
Grossly simplified, this is the source of Google’s magic.”
So how does this work?
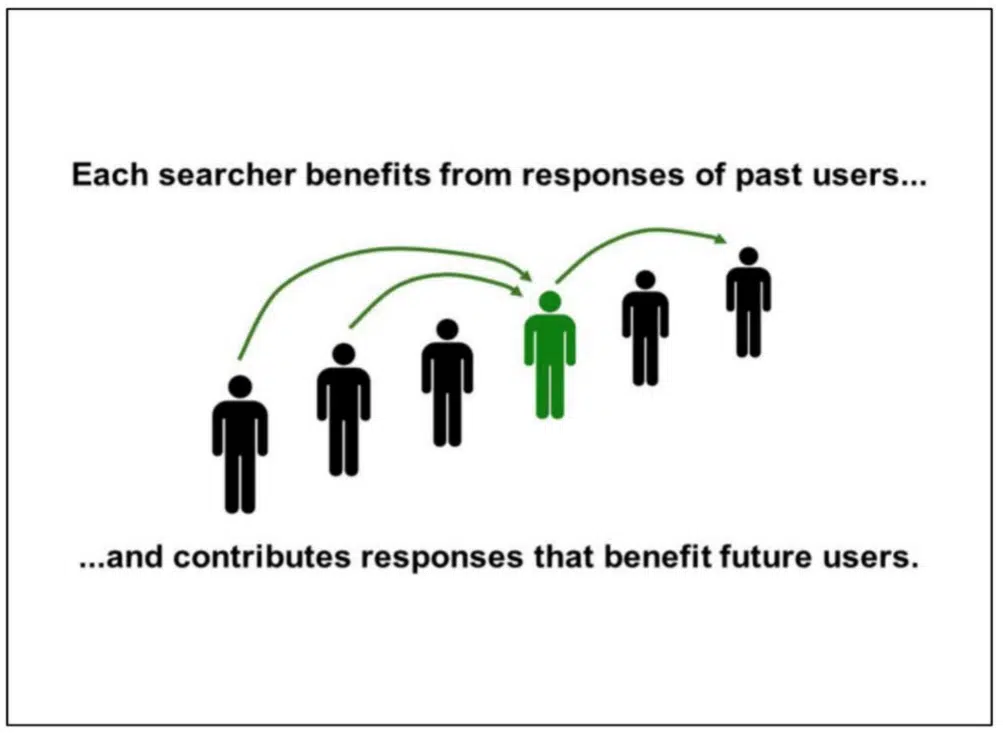
In this slide, Google explains how “each searcher benefits from the responses of past users … and contributes responses that benefit future users”:
“Search keeps working by induction.
This has an important implication.
In designing user experiences, SERVING the user is NOT ENOUGH.
We have to design interactions that also allow us to LEARN from users.
Because that is how we serve the next person, keep the induction rolling, and sustain the illusion that we understand.
Looking to the future, I believe learning from users is also the key to TRULY understanding language.”

And in the final slide, Google sums up with this statement:
- “When fake understanding fails, we look stupid.”
The other four slides are entirely skippable, unless you’re interested in knowing that “Search is a great place to start understanding language. Success has implications far beyond Search.”
Link: Google presentation: Q4 Search All Hands (Dec. 8, 2016) (PDF)
So when you see Google claiming links aren’t a top 3 ranking factor, now you can hopefully start to better understand why. That isn’t to say links are unimportant or that user data is the entire reason – machine learning and natural language processing are other huge pieces, more on that in Bullet points for presentation to Sundar.
Google is looking at end users – how people interact with Search results. Not as individuals – but as a collective.
3. Ranking for Research
It’s unclear who created this presentation, but there are some very interesting findings in here.

In this slide, Google talks about 18 aspects of search quality:
- Relevance
- Page quality
- Popularity
- Freshness
- Localization
- Language
- Centrality
- Topical diversity
- Personalization
- Web ecosystem
- Mobile friendly
- Social fairness
- Optionalization
- Porn demotion
- Spam
- Authority
- Privacy
- User control of spell correction

This slide discusses the shortcomings of live traffic evaluations. Yes, essentially Google is talking about clicks not being a good signal because they are hard to interpret.
- “The association between observed user behavior and search result quality is tenuous. We need lots of traffic to draw conclusions, and individual examples are difficult to interpret.”
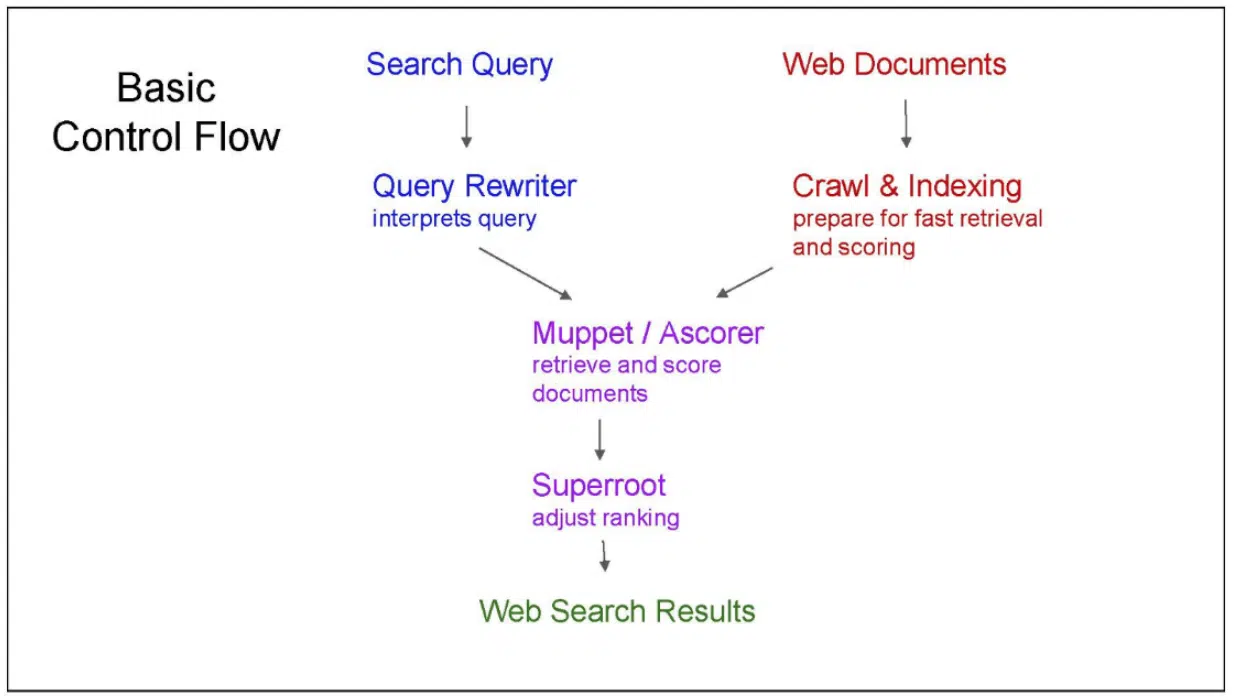
Finally, this slide provides a different illustration of how Google Search result ranking works:
There are some other interesting tidbits in this presentation, though not necessarily tied to ranking. Of note:
- “Attempts to manipulate search results are continuous, sophisticated, and well-funded. Information about how search works should remain need-to-know.” (Slide 5)
- “Keep talk about how search works on a need-to-know basis. Everything we leak will be used against us by SEOs, patent trolls, competitors, etc.” (Slide 10)
- “Do not discuss the use of clicks in search, except on a need-to-know basis with people who understand not to talk about this topic externally. Google has a public position. It is debatable. But please don’t craft your own.” (Slide 11)
Link: Google presentation: Ranking for Research (November 16, 2018) (PDF)
4. Google is magical.
In this presentation, we learn how search really works.
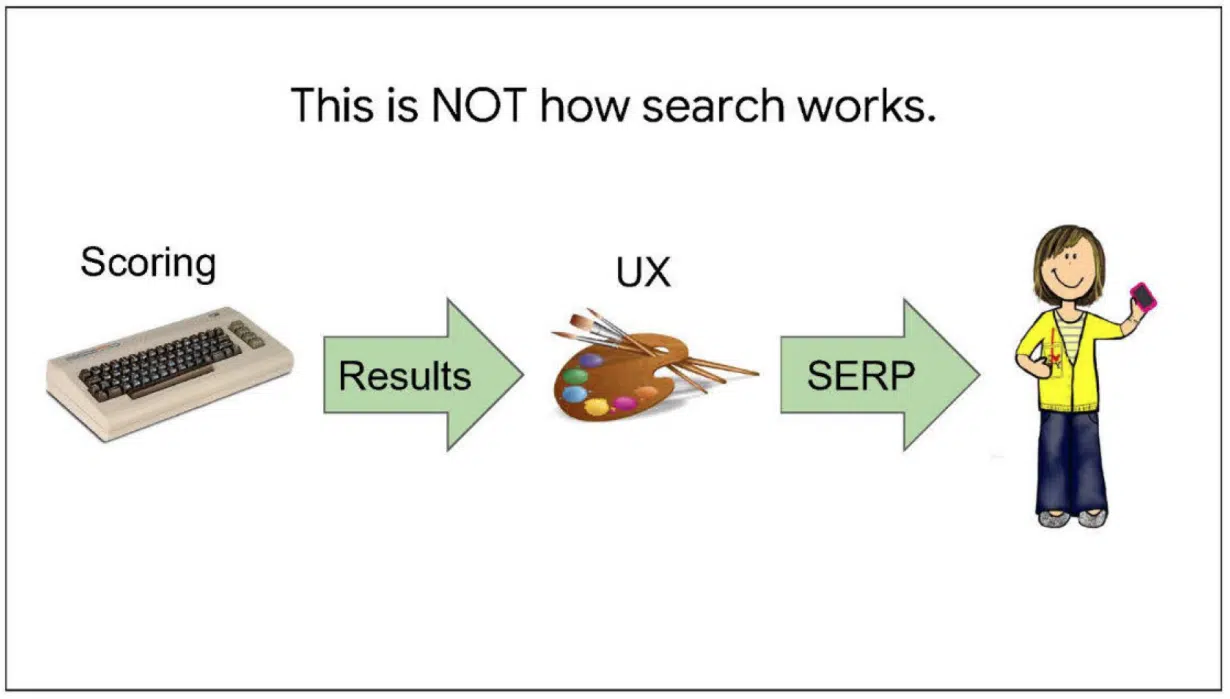
This slide explains how search does not work. From the notes:
“We get a query. Various scoring systems emit data, we slap on a UX, and ship it to the user.
This is not false, just incomplete. So incomplete that a search engine built this way won’t work very well. No magic.”
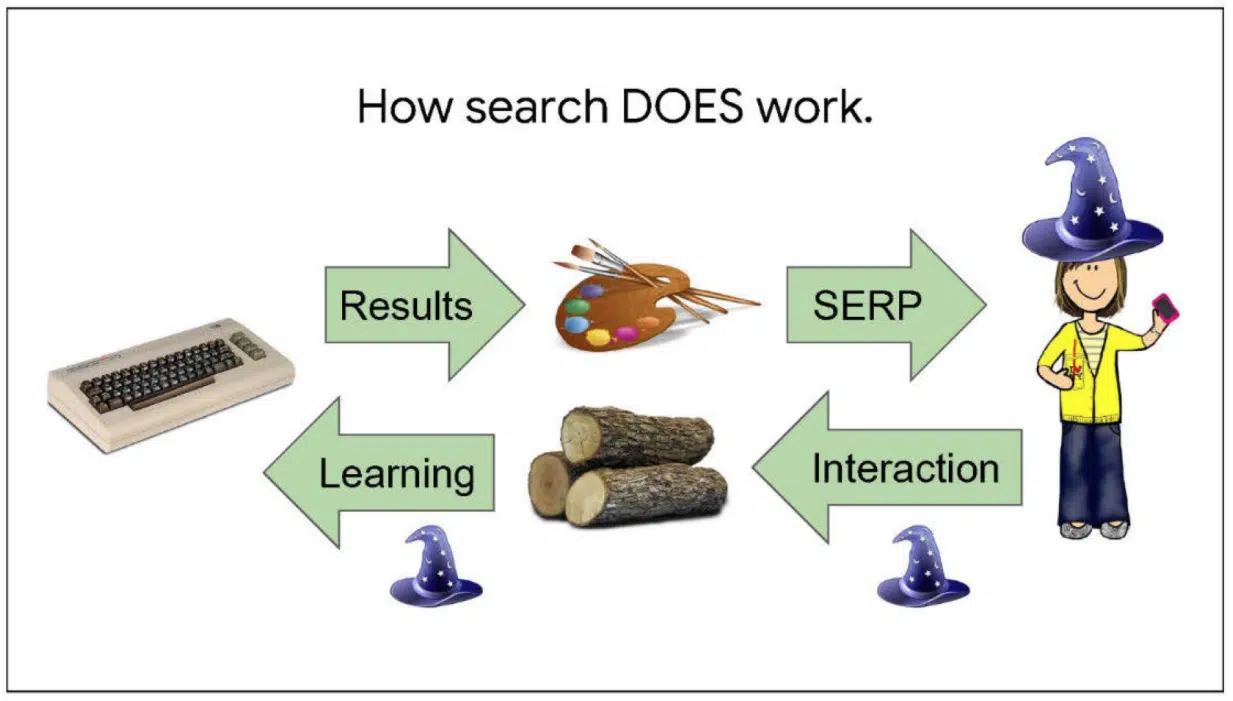
In this slide, we learn how search does work:
“The key is a second flow of information in the reverse direction.
As people interact with search, their actions teach us about the world.
For example, a click might tell us that an image was better than a web result. Or a long look like might mean a KP was interesting.
We log these actions, and then scoring teams extract both narrow and general patterns.”
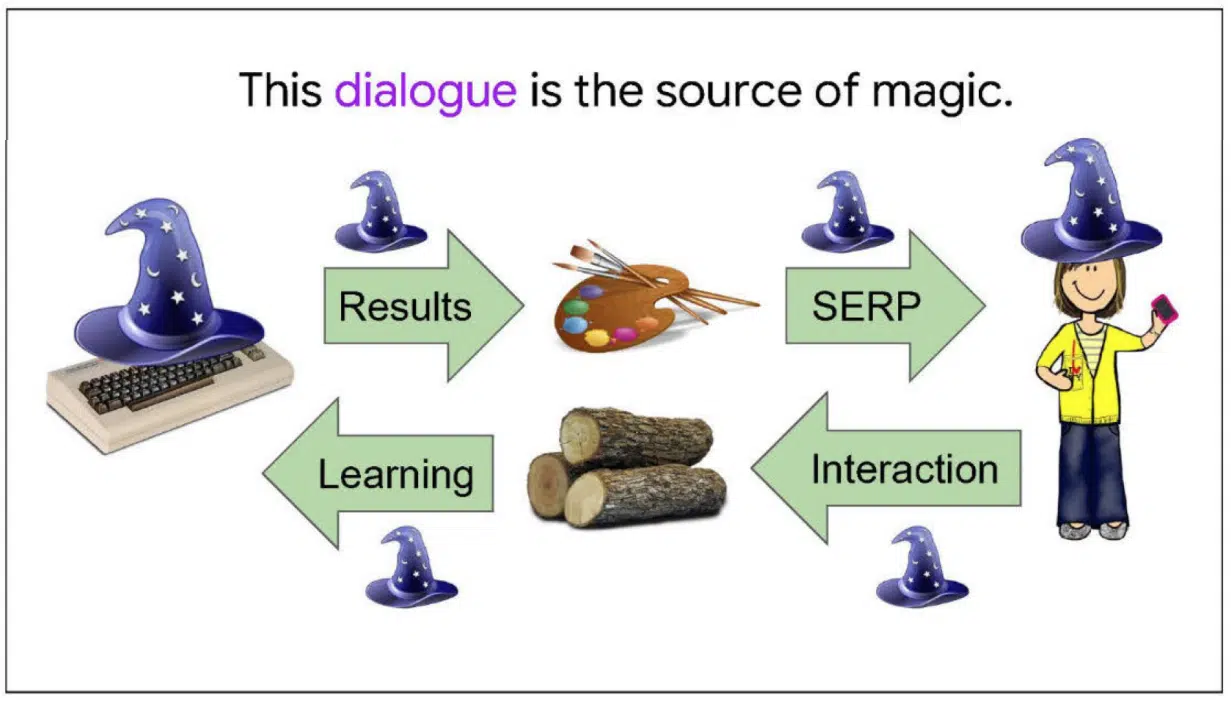
Next, we learn the source of Google’s “magic.” From the notes:
“The source of Google’s magic is this two-way dialogue with users.
With every query, we give a some knowledge, and get a little back. Then we give some more, and get a little more back.
These bits add up. After a few hundred billion rounds, we start lookin’ pretty smart!
This isn’t the only way we learn, but the most effective.”

So how does Google learn more from users? From the notes:
“On the surface, users ask questions and Google answers. That’s our basic business. We can’t screw that up. But we have to quietly turn the tables. One way is to:
- ask the user a question implicitly
- provide necessary background information
- give the user some way to tell us the answer”
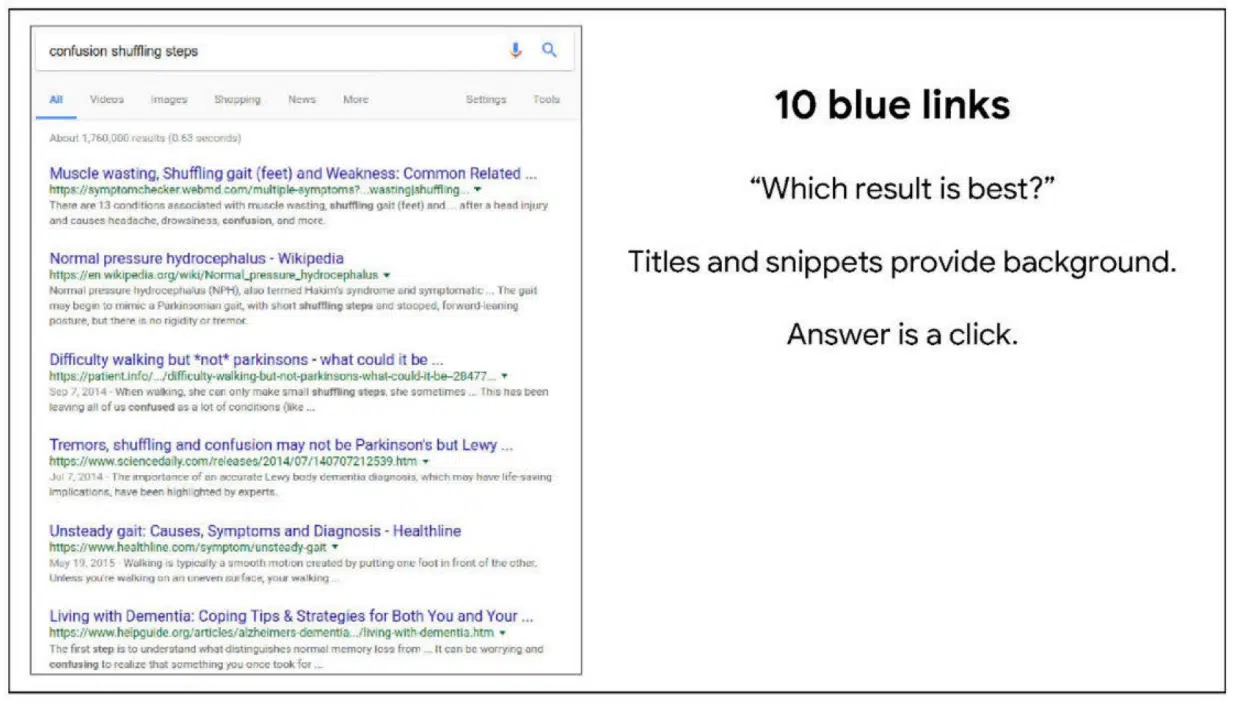
This slide looks at the 10 blue links.
“For example, the ten blue links implicitly pose the question, ‘Which result is best?’
Result previews give background. And the answer is a click.
This is a great UX for learning. For years, Google was mocked for great search results in a bland UI.
But this bland UI made the search results great.”
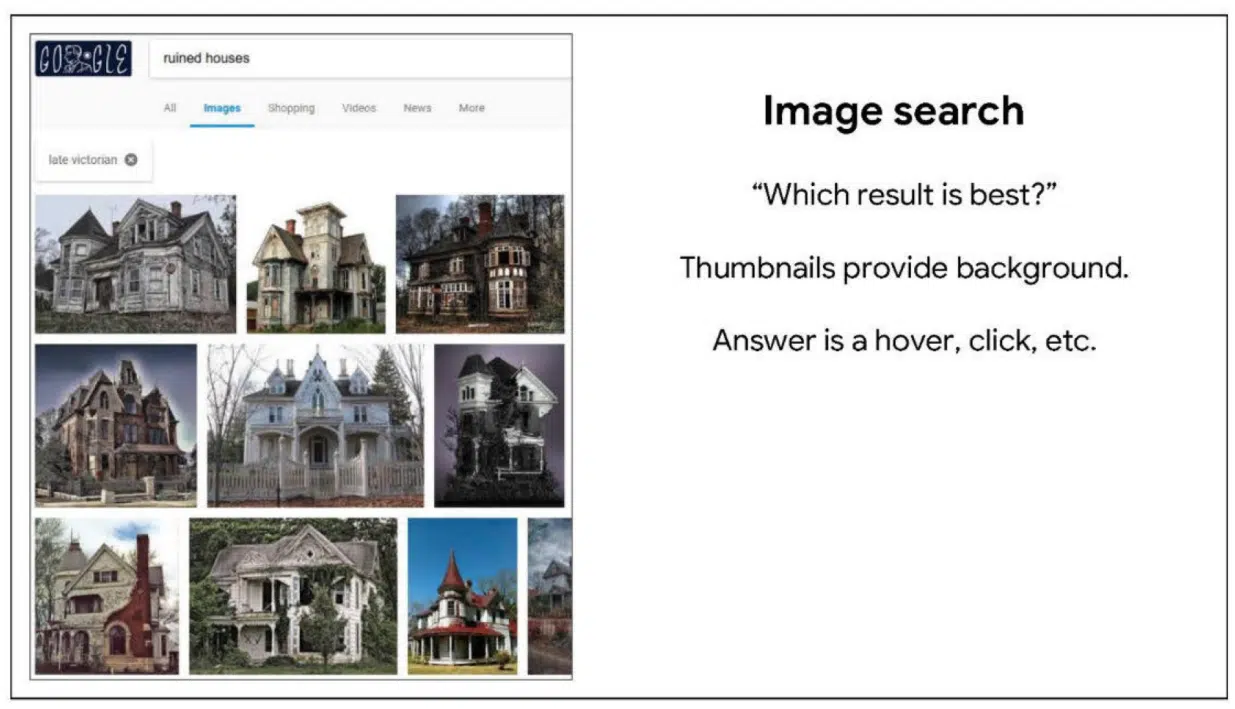
This slide is on Image Search:
“Image search poses a similar question– which do you like best? Thumbnails provide background information, and the user’s answer is logged as a hover, click, or further interaction.”

Finally, knowledge cards:
“For example, some knowledge cards need an extra tap to fully open.
On the left, an extra tap means the user wants lower classifications and an overview.
On the right, the user has too little background information.
More what? How is tapping here different from scrolling down? Users can’t make a good decision, so Taps and clicks are such distinctive events in logs; we should endow every one with meaning.”
Link: Google presentation: Google is magical. (October 30, 2017) (PDF)
5. Logging & Ranking
This presentation discusses the “critical role that logging plays” in ranking and search.
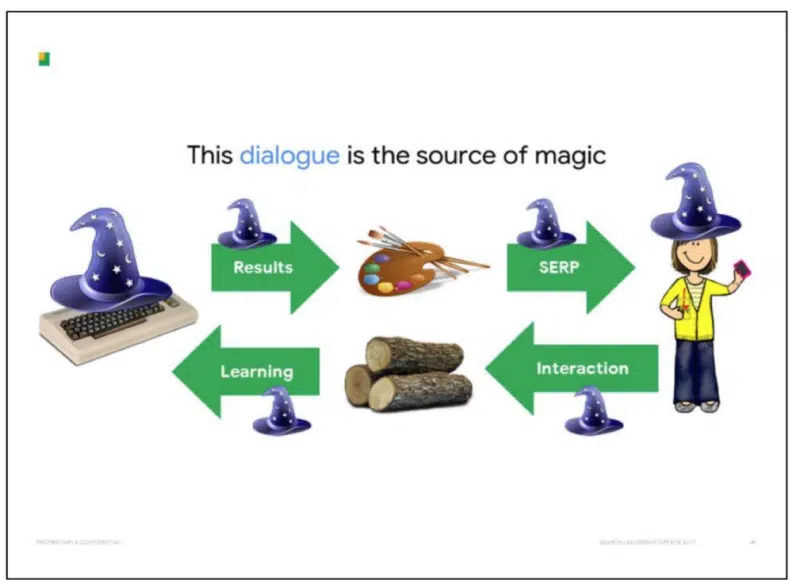
This familiar-looking slide revisits the two-way dialogue being the source of Google’s magic. As explained in the notes:
“Search is a bit like a potluck, where every person brings one dish of food to share. This a great, big spread of food that everyone can enjoy. But it only works because everyone contributes a little bit.
In a similar way, search is powered by a huge mass of knowledge. But it isn’t something we create.
Rather, everyone who comes to search contributes a little bit of knowledge to the system from which everyone can benefit.”

In this slide, Google discusses translating user behaviors. From the slide notes:
“The logs do not contain explicit value judgments– this was a good search results, this was a bad one.
So we have to some how translate the user behaviors that are logged into value judgments.
And the translation is really tricky, a problem that people have worked on pretty steadily for more than 15 years.
People work on it because value judgements are the foundation of Google search.
If we can squeeze a fraction of a bit more meaning out of a session, then we get like a billion times that the very next day.
The basic game is that you start with a small amount of ‘ground truth’ data that says this thing on the search page is good, this is bad, this is better than that.
Then you look at all the associated user behaviors, and say, “Ah, this is what a user does with a good thing! This is what a user does with a bad thing! This is how a user shows preference!’
Of course, people are different and erratic. So all we get is statistical correlations, nothing really reliable.
For example:
[REDACTED]
– If someone clicks on three search results, which one is bad? Well, likely ALL of them, because it is probably a hard query if they clicked 3 results. Challenge is to figure out which one is most promising.”

Finally, this slide discusses how logging supports ranking and Search. From the notes:
“… and here comes the part I warned you about. I’m selling something. I’m selling the idea of the logs term keeping the needs of the ranking team in mind. Pretty please with sugar on top.
But the basic reason is that the ranking team is really weird in one more way, and that is business impact.
As I mentioned, not one system, but a great many within ranking are built on logs.
This isn’t just traditional systems, like the one I showed you earlier, but also the most cutting-edge machine learning systems, many of which we’ve announced externally– RankBrain, RankEmbed, and DeepRank.
Web ranking is only a part of search, but many search features use web results to interpret the query and trigger accordingly.
So supporting ranking supports search as a whole.
But even beyond this, technologies developed in search spread out across the company to Ads, YouTube, Play, and elsewhere.
So– I’m not in finance– but grossly speaking, I think a huge amount of Google business is tied to the use of logs in ranking.”
Link: Google presentation: Logging & Ranking (May 8, 2020) (PDF)
6. Mobile vs. desktop ranking
This newsletter dove into the differences between desktop and mobile search ranking, user intents and user satisfaction – at a time when mobile traffic was starting to surpass desktop traffic on some days.
Google did a comparison of metrics, including:
- CTR
- Manual refinement
- Queries per task
- Query length (in char)
- Query lengths (in word)
- Abandonment
- Average Click Position
- Duplicates
Based on the findings, one of the recommendations was:
- “Separate mobile ranking signals or evaluation reflecting different intents. Mobile queries often have different intents, and we may need to incorporate additional or supplementary signals reflecting these intents into our ranking framework. As discussed earlier, it is desirable that these signals handle local-level breakdowns properly.
7. Bullet points for presentation to Sundar
Nothing surprising in this document (it’s unclear who wrote it), but one interesting bullet on BERT and Search ranking:
- “Early experiments with BERT applied to several other areas in Search, including Web Ranking, suggest very significant improvements in understanding queries, documents and intents.”
- “While BERT is revolutionary, it is merely the beginning of a leap in Natural Language Understanding technologies.”
Link: Google document: Bullet points for presentation to Sundar (Sept. 17, 2019) (PDF)