




In deep learning, Transformer neural networks have garnered significant attention for their effectiveness in various domains, especially in natural language processing and emerging applications like computer vision, robotics, and autonomous driving. However, while enhancing performance, the ever-increasing scale of these models brings about a substantial rise in compute cost and inference latency. The fundamental challenge lies in leveraging the advantages of larger models without incurring impractical computational burdens.
The current landscape of deep learning models, particularly Transformers, showcases remarkable progress across diverse domains. Nevertheless, the scalability of these models often needs to be improved due to the escalating computational requirements. Prior efforts, exemplified by sparse mixture-of-experts models like Switch Transformer, Expert Choice, and V-MoE, have predominantly focused on efficiently scaling up network parameters, mitigating the increased compute per input. However, a research gap exists concerning the scaling up of the token representation dimension itself. Enter AltUp is a novel method introduced to address this gap.
AltUp stands out by providing a method to augment token representation without amplifying the computational overhead. This method ingeniously partitions a widened representation vector into equal-sized blocks, processing only one block at each layer. The crux of AltUp’s efficacy lies in its prediction-correction mechanism, enabling the inference of outputs for the non-processed blocks. By maintaining the model dimension and sidestepping the quadratic increase in computation associated with straightforward expansion, AltUp emerges as a promising solution to the computational challenges posed by larger Transformer networks.
AltUp’s mechanics delve into the intricacies of token embeddings and how they can be widened without triggering a surge in computational complexity. The method involves:
- Invoking a 1x width transformer layer for one of the blocks.
- Termed the “activated” block.
- Concurrently employing a lightweight predictor.
This predictor computes a weighted combination of all input blocks, and the predicted values, along with the computed value of the activated block, undergo correction through a lightweight corrector. This correction mechanism facilitates the update of inactivated blocks based on the activated ones. Importantly, both prediction and correction steps involve minimal vector additions and multiplications, significantly faster than a conventional transformer layer.
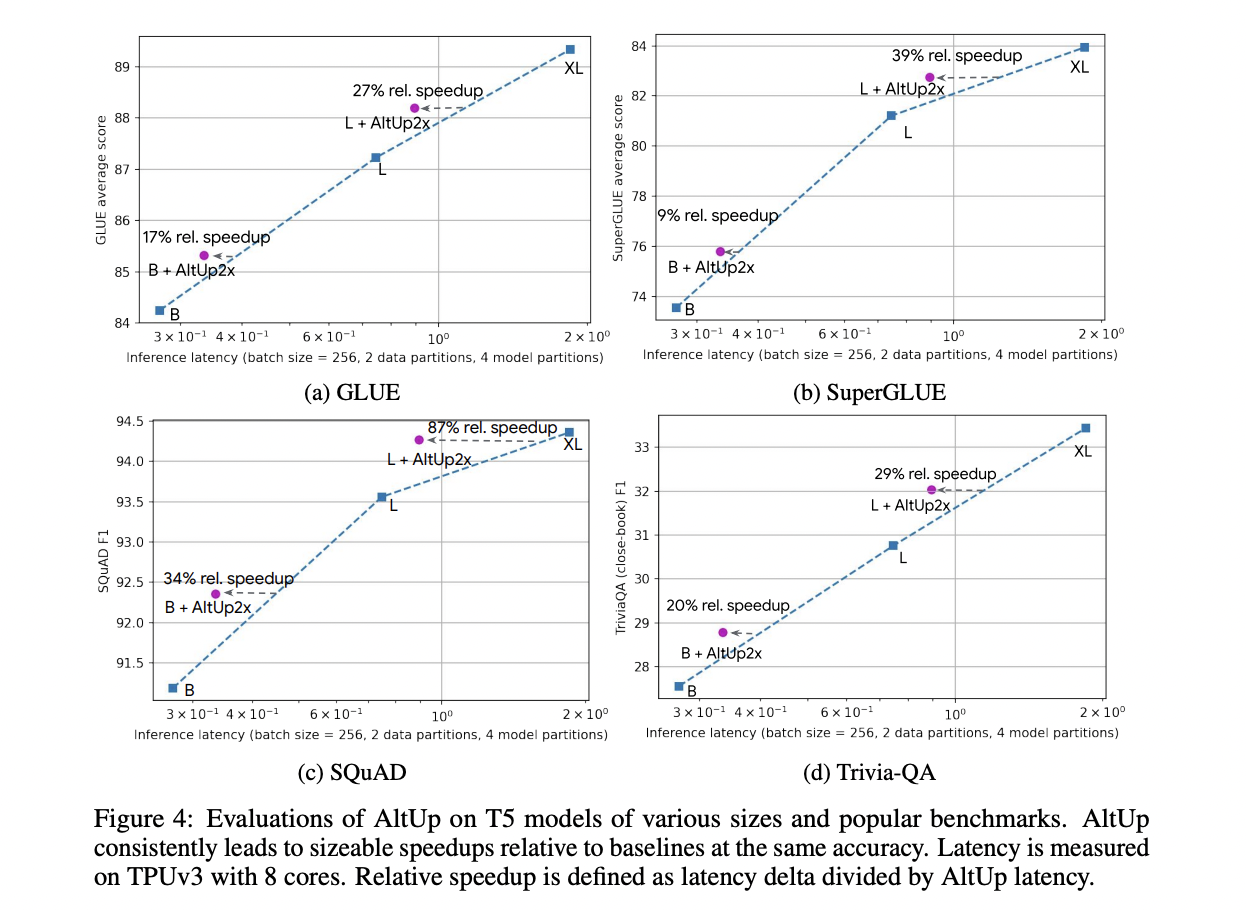
The evaluation of AltUp on T5 models across benchmark language tasks demonstrates its consistent ability to outperform dense models at the same accuracy. Notably, a T5 Large model augmented with AltUp achieves notable speedups of 27%, 39%, 87%, and 29% on GLUE, SuperGLUE, SQuAD, and Trivia-QA benchmarks, respectively. AltUp’s relative performance improvements become more pronounced when applied to larger models, underscoring its scalability and enhanced efficacy as model size increases.

In conclusion, AltUp emerges as a noteworthy solution to the long-standing challenge of efficiently scaling up Transformer neural networks. Its ability to augment token representation without a proportional increase in computational cost holds significant promise for various applications. The innovative approach of AltUp, characterized by its partitioning and prediction-correction mechanism, offers a pragmatic way to harness the benefits of larger models without succumbing to impractical computational demands.
news|news|news|news|news|news|news|news|news|news|news|news|news|news
The researchers’ extension of AltUp, known as Recycled-AltUp, further showcases the adaptability of the proposed method. Recycled-AltUp, by replicating embeddings instead of widening the initial token embeddings, demonstrates strict improvements in pre-training performance without introducing perceptible slowdown. This dual-pronged approach, coupled with AltUp’s seamless integration with other techniques like MoE, exemplifies its versatility and opens avenues for future research in exploring the dynamics of training and model performance.
AltUp signifies a breakthrough in the quest for efficient scaling of Transformer networks, presenting a compelling solution to the trade-off between model size and computational efficiency. As outlined in this paper, the research team’s contributions mark a significant step towards making large-scale Transformer models more accessible and practical for a myriad of applications.
Check out the Paper and Google Article. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.



