




Reinforcement Learning (RL) is a subfield of Machine Learning in which an agent takes suitable actions to maximize its rewards. In reinforcement learning, the model learns from its experiences and identifies the optimal actions that lead to the best rewards. In recent years, RL has improved significantly, and it today finds its applications in a wide range of fields, from autonomous cars to robotics and even gaming. There have also been major advancements in the development of libraries that facilitate easier development of RL systems. Examples of such libraries include RLLib, Stable-Baselines 3, etc.
In order to make a successful RL agent, there are certain issues that need to be addressed, such as tackling delayed rewards and downstream consequences, finding a balance between exploitation and exploration, and considering additional parameters (like safety considerations or risk requirements) to avoid catastrophic situations. The current RL libraries, although quite powerful, do not tackle these problems adequately, and hence, the researchers at Meta have released a library called Pearl that considers the above-mentioned issues and allows users to develop versatile RL agents for their real-world applications.
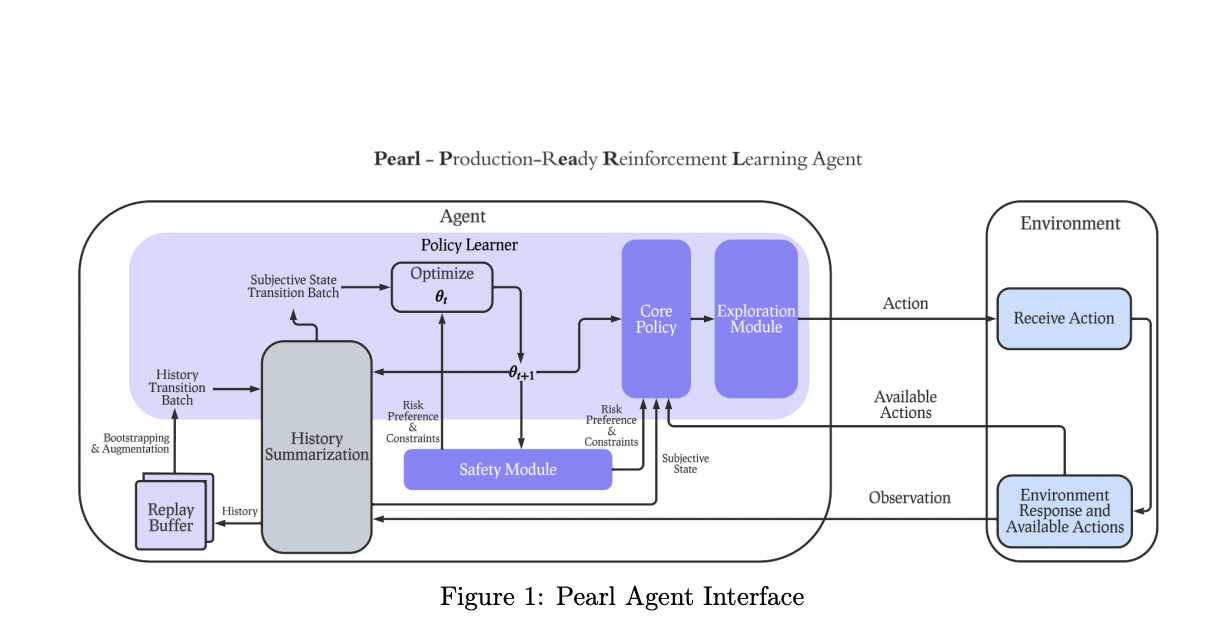
Pearl has been built on PyTorch, which makes it compatible with GPUs and distributed training. The library also provides different functionalities for testing and evaluation. Pearl’s main policy learning algorithm is called PearlAgent, which has features like intelligent exploration, risk sensitivity, safety constraints, etc., and has components like offline and online learning, safe learning, history summarization, and replay buffers.
An effective RL agent must be able to use an offline learning algorithm to learn as well as evaluate a policy. Moreover, for offline and online training, the agent should have some security measures for data collection and policy learning. Along with that, the agent should also have the ability to learn state representations using different models and summarize histories into state representations to filter out undesirable actions. Lastly, the agent should also be able to reuse the data efficiently using a replay buffer to enhance learning efficiency. The researchers at Meta have incorporated all the above-mentioned features into the design of Pearl (more specifically, PearlAgent), making it a versatile and effective library for the design of RL agents.
Researchers compared Pearl with existing RL libraries, evaluating factors like modularity, intelligent exploration, and safety, among others. Pearl successfully implemented all these capabilities, distinguishing itself from competitors that failed to incorporate all the necessary features. For example, RLLib supports offline RL, history summarization, and replay buffer but not modularity and intelligent exploration. Similarly, SB3 fails to incorporate modularity, safe decision-making, and contextual bandit. This is where Pearl stood out from the rest, having all the features considered by the researchers.
Pearl is also in progress to support various real-world applications, including recommender systems, auction bidding systems, and creative selection, making it a promising tool for solving complex problems across different domains. Although RL has made significant advancements in recent years, its implementation to solve real-world problems is still a daunting task, and Pearl has showcased its abilities to bridge this gap by offering comprehensive and production-grade solutions. With its unique set of features like intelligent exploration, safety, and history summarization, it has the potential to serve as a valuable asset for the broader integration of RL in real-world applications.
Check out the Paper, Github, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE||RE|RE|RE|RE|RE|
RE|RE|RE|RE|RE|||RE|RE|RE|RE|RE|RE|RE|RE|RE|RE||RE|RE|RE|RE|RE|RE|RE|
RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE|RE
I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.



