




Natural language processing and computer vision are only examples of the fields where generative pre-trained models have succeeded incredibly. In particular, a viable strategy for constructing foundation models is to combine varied large-scale datasets with pre-trained transformers. The study investigates the feasibility of foundation models to further research in cellular biology and genetics by drawing connections between language and biological constructions (where texts constitute genes and respectively characterize words and cells). Researchers have been at the forefront of building scGPT, a foundation model for single-cell biology based on a generative pre-trained transformer spanning a repository of over a million cells, using the growing body of single-cell sequencing data. Results show that scGPT, a pre-trained generative transformer, efficiently extracts key biological insights related to genes and cells. The script can be improved for use in various applications by using transfer learning in new ways. These challenges include gene network inference, genetic perturbation prediction, and multi-batch integration. View the scGPT source code.
By facilitating detailed characterization of individual cell types and enhancing our knowledge of disease pathogenesis, single-cell RNA sequencing (scRNA-seq) paves the way for the investigation of cellular heterogeneity, the tracking of lineages, the elucidation of pathogenic mechanisms, and the development of patient-specific therapeutic approaches.
Given the exponential growth of sequencing data, it is urgent to create methods that can effectively leverage, enhance, and adapt to these new trends. The generative pre-training of foundation models is an effective strategy for overcoming this difficulty. Learning from massive datasets, generative pre-training has recently seen extraordinary success in various domains. Popular uses include NLG (natural language generation) and computer vision. These baseline models, including DALL-E2 and GPT-4, are based on the tenet of pre-training transformers on large-scale heterogeneous datasets that can be easily adapted to specific downstream tasks and scenarios. Not only that, but these pre-trained generative models always perform better than their custom-trained counterparts.
Researchers take cues from the NLG self-supervised pre-training method to improve the modeling of massive amounts of single-cell sequencing data. It has been proven that the self-attention transformer is a useful and efficient framework for modeling input tokens of text.
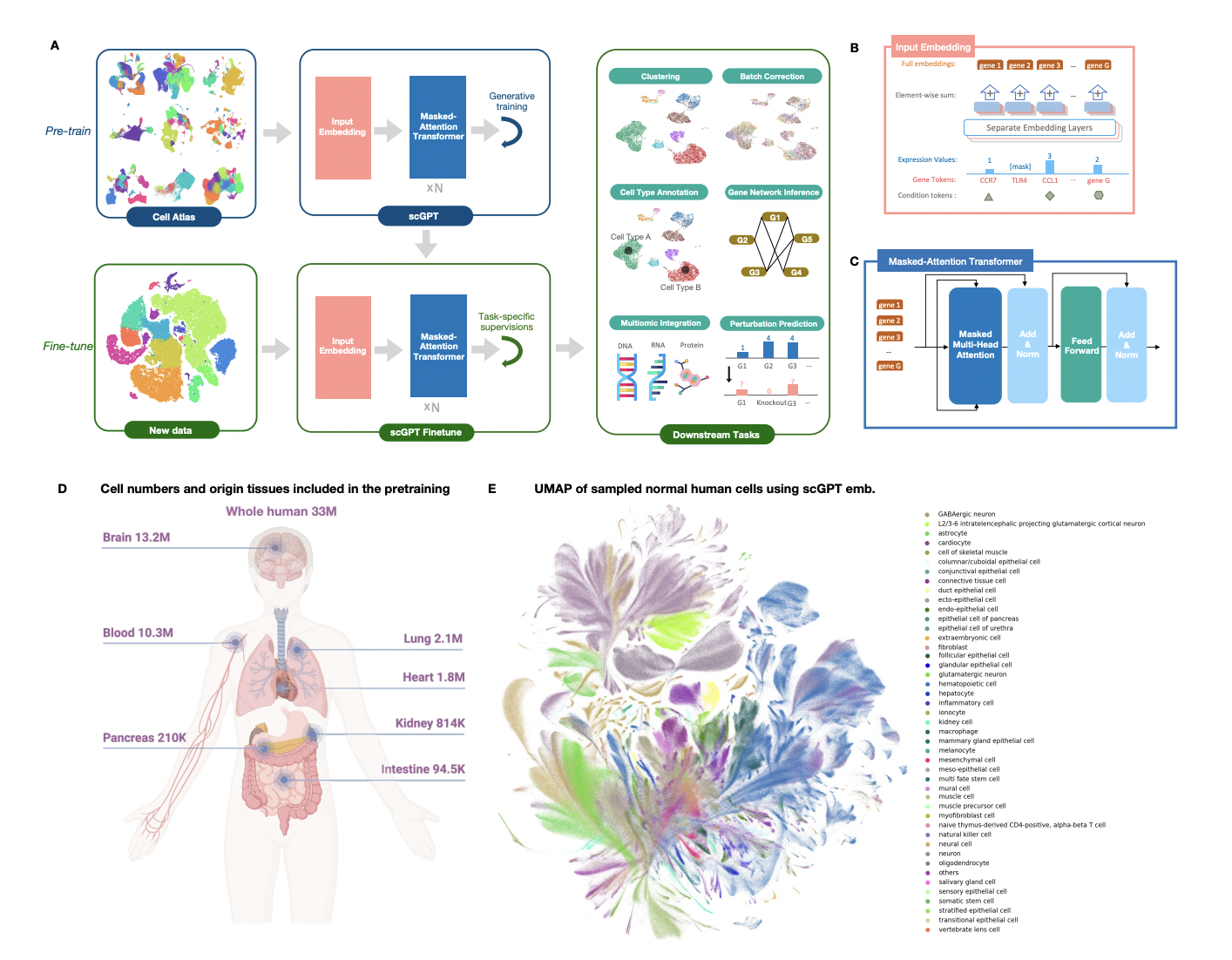
Using generative pre-training on more than a million cells, these scientists offer the first attempt to construct a single-cell foundation model, dubbed scGPT. They present novel approaches to pre-training massive amounts of single-cell omic data, addressing both the methodological and engineering issues that arise. They employ an in-memory data structure with quick access to store hundreds of datasets, allowing them to deal with massive amounts of data. They modify the transformer architecture to learn cell and gene representations simultaneously and build a unified generative pre-training approach tailored to non-sequential omic data. To enable the use of the pre-trained model in various downstream tasks, they also supply standard pipelines with task-specific objectives for model fine-tuning.
Through these three components, the scGPT model highlights the revolutionary potential of the single-cell foundation concept. That begins with scGPT, the first large-scale generative foundation model that supports transfer learning to various downstream activities. They demonstrate the efficacy of the “pre-training universally, fine-tuning on demand” approach as a generalist solution for computational applications in single-cell omics by achieving state-of-the-art performance on cell type annotation, genetic perturbation prediction, batch correction, and multi-omic integration.
In particular, scGPT is the only base model capable of incorporating scATAC-seq data and other single-cell omics. Second, scGPT reveals important biological insights into condition-specific gene-gene interactions by comparing gene embeddings and attention weights between the refined and raw pre-trained models. Third, the results show a scaling law: better pre-trained embeddings and higher performance on downstream tasks result from using more data in the pre-training phase. This discovery underlines the promising possibility that foundation models can steadily improve as more and more sequencing data becomes available to the research community. In light of these results, they hypothesize that using pre-trained foundation models will significantly increase our knowledge of cell biology and lay the groundwork for future advancements in the field. Making the scGPT models and workflow publicly available allows research in these and related fields to be strengthened and accelerated.
The script is a novel generative pretrained foundation model that uses pre-trained transformers to make sense of a large volume of single-cell data, as described by the study’s authors. Self-supervised pre-training has proven effective in language models such as chatGPT and GPT4. In the study of single cells, they used the same strategy to decipher intricate biological connections. To better model different facets of cellular processes, scGPT uses transformers to learn both gene and cell embeddings simultaneously. Single-cell GPT (scGPT) captures gene-to-gene interactions at the single-cell level, adding a new degree of interpretability by using the attention mechanism of transformers.
Researchers used extensive studies in zero-shot and fine-tuning scenarios to prove pre-training’s value. The trained model is already a feature extractor for any dataset. It demonstrates impressive extrapolation ability, displaying substantial cell clumping in zero-shot studies. In addition, there is a high degree of congruence between the learned gene networks in scGPT and previously established functional relationships. We have faith in the model’s ability to discover relevant discoveries in single-cell biology because it captures gene-gene interactions and reflects known biological information effectively. In addition, with some fine-tuning, the information learned by the pre-trained model can be used for various subsequent tasks. The optimized scGPT model regularly beats models trained from scratch on tasks like cell type annotation, multi-batch, and multi-omic integration. This shows how the pre-trained model benefits subsequent tasks by improving accuracy and biological relevance. Overall, the tests demonstrate the usefulness of pre-training in scGPT, demonstrating its capacity to generalize, capture gene networks, and enhance performance in subsequent tasks utilizing transfer learning.
Key Features
- The generalist strategy allows for integrated multi-omic analysis and perturbation prediction to be performed using a single model for a single-cell study.
- We may identify condition-specific gene-gene interactions using learned attention weights and gene embeddings.
- It identified a scaling law demonstrating the continual improvement of model performance with increasing data load.
- There are now many pre-trained foundation models for different solid organs available in the scGPT model zoo (see github) and a comprehensive pan-cancer model. Get started digging into the data using the best possible starting point model.
Pre-training is expected to take place on a much larger dataset that includes multi-omic data, spatial omics, and a wide range of illness states. The model can learn causal linkages and estimate how genes and cells respond over time if perturbation and temporal data are included in the pre-training phase. To better comprehend and interpret the pre-trained model’s learnings, validating the model on a broader set of biologically significant tasks would be ideal. Additionally, they aim to investigate context-aware knowledge for single-cell data. The pre-trained model must grasp and adapt to new jobs and environments without additional fine-tuning in a zero-shot configuration. They can improve scGPT’s utility and applicability in numerous study contexts by teaching it to understand various studies’ subtleties and unique needs. They expect the pre-training paradigm to be easily implemented in single-cell research and to lay the groundwork for capitalizing on the accumulated knowledge in the rapidly expanding cell atlases.
Check out the Paper and Github Link. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools:
- Aragon: Get stunning professional headshots effortlessly with Aragon.
- StoryBird AI: Create personalized stories using AI
- Taplio: Transform your LinkedIn presence with Taplio’s AI-powered platform
- Otter AI: Get a meeting assistant that records audio, writes notes, automatically captures slides, and generates summaries.
- Notion: Notion AI is a robust generative AI tool that assists users with tasks like note summarization
- tinyEinstein: tinyEinstein is an AI Marketing manager that helps you grow your Shopify store 10x faster with almost zero time investment from you.
- AdCreative.ai: Boost your advertising and social media game with AdCreative.ai – the ultimate Artificial Intelligence solution.
- SaneBox: SaneBox’s powerful AI automatically organizes your email for you, and the other smart tools ensure your email habits are more efficient than you can imagine
- Motion: Motion is a clever tool that uses AI to create daily schedules that account for your meetings, tasks, and projects.
🚀 Check Out 100’s AI Tools in AI Tools Club
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.



