





The performance of large language models (LLMs) has been impressive across many different natural language processing (NLP) applications. In recent studies, LLMs have been proposed as task-specific training data generators to reduce the necessity of task-specific data and annotations, especially for text classification. Though these efforts have demonstrated the usefulness of LLMs as data producers, they have largely centered on improving the training step, when the generated data are used to train task-specific models, leaving the upstream data creation process untouched. To query LLMs, the prevalent method uses a single class conditional prompt, which may reduce the variety of provided data and perpetuate the inherent systematic biases of LLMs.
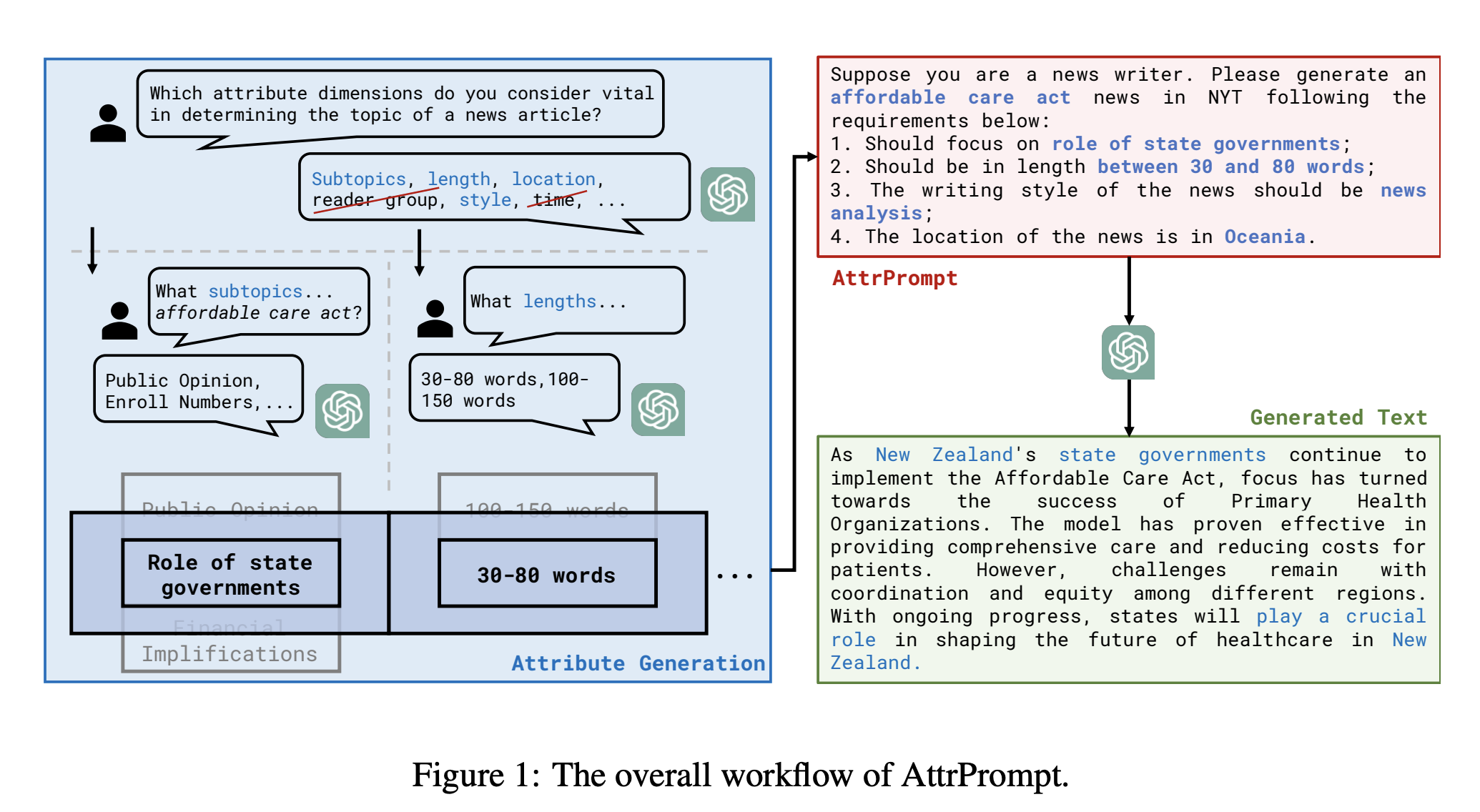
A new study by Georgia Tech, University of Washington, UIUC, and Google Research analyzes four difficult subject classification tasks with large cardinality from different domains. It anchors the LLM to ChatGPT for its ability to write high-quality, human-like language. The team primarily uses data attributes to evaluate the level of bias and diversity within the created training set. Specifically, data attributes consist of several attribute dimensions and various attribute values, each representing a possible realization of the attributes themselves.
The researchers used a trained attribute classifier to analyze the attribute bias in the SimPrompt-generated dataset. They investigate how different attributes can affect a model’s final results. To generate attributed data, they use ChatGPT and add constraints to the questions with certain values for the necessary characteristics. The researchers find that models trained on datasets generated with random characteristics perform significantly better than those trained on datasets with fixed attributes, highlighting the significance of attribute variation in the generated dataset.
The team suggests generating data using diversely attributed prompts to reduce attribute biases and increase the attribute diversity of the generated data. Using the LLM, an interactive, semi-automated process is first engaged to determine the appropriate attribute dimensions and values for a given classification task. The standard class-conditional prompt for LLM data queries is then replaced by more complex inquiries generated by randomly combined properties. They have coined the term “AttrPrompt” to describe these various attributable triggers.
The researchers empirically evaluate the created datasets on the four classification tasks by comparing the results of models trained under two scenarios: 1) only on the generated dataset and 2) on a merged dataset, including the genuine training set and the generated set. The dataset created using AttrPrompt performs far better than the dataset created with SimPrompt in both cases. Their results further show that AttrPrompt is superior to SimPrompt regarding data/budget efficiency and flexibility toward a wide range of model sizes and LLM-as-training-data-generator strategies.
AttrPrompt is notable because it provides the same performance as SimPrompt while only requiring 5% of the querying cost of ChatGPT that SimPrompt necessitates. Finally, they show for the first time that AttrPrompt beats SimPrompt across all evaluation criteria by extending the LLM-as-training-data-generator paradigm to the more difficult multi-label classification problems.
Check Out the Paper and Github Link. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools:
🚀 Check Out 100’s AI Tools in AI Tools Club
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.



