




Enormous large language models (LLMs) can exhibit appealing skills like producing human-like discourse and responding to complicated inquiries because they have been trained at scale on large text corpora. While undoubtedly amazing, most cutting-edge LLMs are trained on text-only data downloaded from the Internet. They frequently cannot absorb concepts based on the actual world because they need to be exposed to rich visual clues. As a result, most language models now in use show limits on tasks that need visual reasoning and grounding and are also unable to generate visuals. In this article, they demonstrate how to effectively use a frozen LLM’s capabilities for multimodal (picture and text) input and output.
They train the language model to learn a new [RET] token that stands in for an image for image-text retrieval. They also know linear mapping using contrastive learning to map the [RET] embeddings for a caption to be close to the visual embeddings for its associated picture. Only the weights of the linear layers and the [RET] token embedding are updated during training, with most of the model remaining frozen. As a result, their suggested approach is highly memory and computationally efficient. Once trained, a model demonstrates several skills. It has a new multimodal conversation and reasoning skills in addition to the original text-only LLM’s ability to create text. Their suggested approach is model-independent and may be used to base future releases of stronger or bigger LLMs.
The language model is trained to learn a new [RET] token representing an image, and contrastive learning is used to know a linear mapping that maps the [RET] embeddings for a caption to be close to the visual embeddings for its matched picture. Only the weights of the linear layers and the [RET] token embedding are updated during training, leaving most of the model fixed. As a result, their suggested approach is highly memory and computationally efficient. 1Once taught, their model demonstrates several skills. It has a new multimodal conversation and reasoning skills in addition to the original text-only LLM’s ability to create text. Their suggested approach is model-independent and may be used to base future releases of stronger or bigger LLMs.
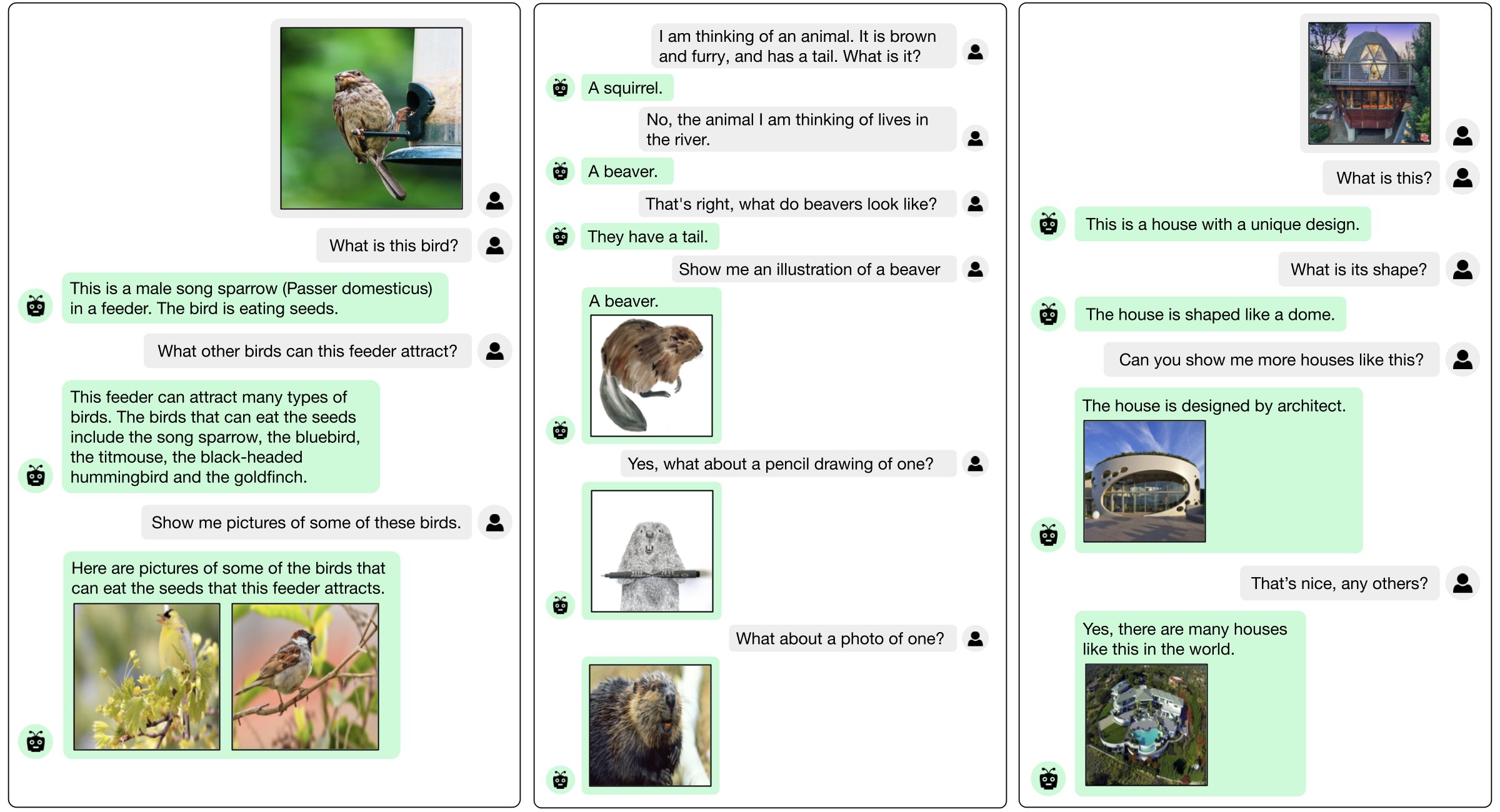
Showcasing the increased sensitivity of text-to-image retrieval performed by autoregressive LLMs. One of their primary contributions is the Frozen Retrieval Over Multimodal Data for Autoregressive Generation (FROMAGe) model, effectively trained by visually anchoring LLMs through picture captioning and contrastive learning. While previous algorithms require webscale interleaved image-text data, FROMAGe develops strong few-shot multimodal capabilities from image caption pairings alone. Their method is more accurate on lengthy and complicated free-form text than previous models. Demonstrating how pretrained text-only LLMs’ current skills, including in-context learning, input sensitivity, and conversation creation, may be used for tasks that require visual input.
They show: (1) contextual image retrieval from sequences of interspersed pictures and text; (2) good zero-shot performance on visual conversation; and (3) enhanced discourse context sensitivity for image retrieval. Their results open the door to models that can learn from and produce lengthy, coherent multimodal sequences. They also highlight the capabilities of pretrained text-only LLMs on visually based tasks. To promote more research and development, their code and pretrained models will be made available to the general public soon.
Check out the Paper, Project, and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.



