




Speech recognition technology has become a cornerstone for various applications, enabling machines to understand and process human speech. The field continuously seeks advancements in algorithms and models to improve accuracy and efficiency in recognizing speech across multiple languages and contexts. The main challenge in speech recognition is developing models that accurately transcribe speech from various languages and dialects. Models often need help with the variability of speech, including accents, intonation, and background noise, leading to a demand for more robust and versatile solutions.
Researchers have been exploring various methods to enhance speech recognition systems. Existing solutions have often relied on complex architectures like Transformers, which, despite their effectiveness, face limitations, particularly in processing speed and the nuanced task of accurately recognizing and interpreting a wide array of speech nuances, including dialects, accents, and variations in speech patterns.
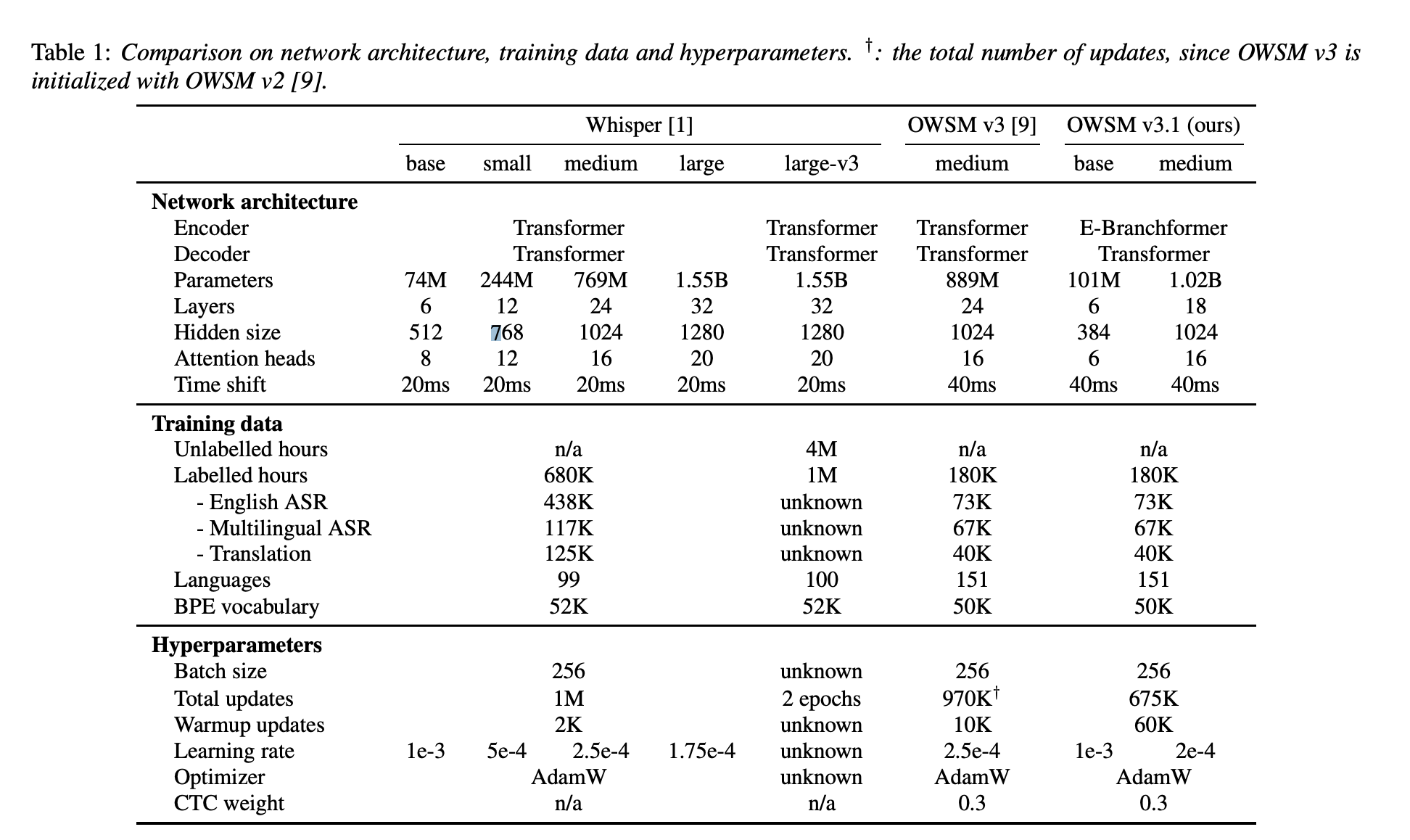
The Carnegie Mellon University and Honda Research Institute Japan research team introduced a new model, OWSM v3.1, utilizing the E-Branchformer architecture to address these challenges. OWSM v3.1 is an improved and faster Open Whisper-style Speech Model that achieves better results than the previous OWSM v3 in most evaluation conditions.
The previous OWSM v3 and Whisper both utilize the standard Transformer encoder-decoder architecture. However, recent advancements in speech encoders such as Conformer and Branchformer have improved performance in speech processing tasks. Hence, the E-Branchformer is employed as the encoder in OWSM v3.1, demonstrating its effectiveness at a scale of 1B parameters. OWSM v3.1 excludes the WSJ training data used in OWSM v3, which had fully uppercased transcripts. This exclusion leads to a significantly lower Word Error Rate (WER) in OWSM v3.1. It also demonstrates up to 25% faster inference speed.
OWSM v3.1 demonstrated significant achievements in performance metrics. It outperformed its predecessor, OWSM v3, in most evaluation benchmarks, achieving higher accuracy in speech recognition tasks across multiple languages. Compared to OWSM v3, OWSM v3.1 shows improvements in English-to-X translation in 9 out of 15 directions. Although there may be a slight degradation in some directions, the average BLEU score is slightly improved from 13.0 to 13.3.
In conclusion, the research significantly strides towards enhancing speech recognition technology. By leveraging the E-Branchformer architecture, the OWSM v3.1 model improves upon previous models in terms of accuracy and efficiency and sets a new standard for open-source speech recognition solutions. By releasing the model and training details publicly, the researchers’ commitment to transparency and open science further enriches the field and paves the way for future advancements.
Check out the Paper and Demo. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
link,link,link,link,link,link,link,link,link,link,link,link,link,link,link,link,
link,link,link,link,link,link,link,link,link,link,link,link,link,link,link,link,link,
link,link,link,link,link,link,link,link,link,link,link,link,link,link,link,link
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.



