






Search is hard, as Seth Godin wrote in 2005.
I mean, if we think SEO is hard (and it is) imagine if you were trying to build a search engine in a world where:
- The users vary dramatically and change their preferences over time.
- The technology they access search advances every day.
- Competitors nipping at your heels constantly.
On top of that, you’re also dealing with pesky SEOs trying to game your algorithm gain insights into how best to optimize for your visitors.
That’s going to make it a lot harder.
Now imagine if the main technologies you need to lean on to advance came with their own limitations – and, perhaps worse, massive costs.
Well, if you’re one of the writers of the recently published paper, “End-to-End Query Term Weighting” you see this as an opportunity to shine.
What is end-to-end query term weighting?
End-to-end query term weighting refers to a method where the weight of each term in a query is determined as part of the overall model, without relying on manually programmed or traditional term weighting schemes or other independent models.
What does that look like?
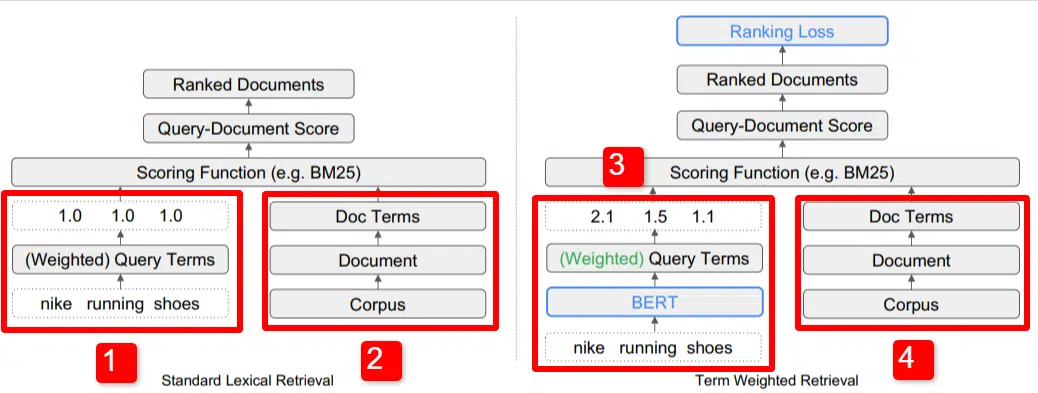
Here we see an illustration of one of the key differentiators of the model outlined in the paper (Figure 1, specifically).
On the right side of the standard model (2) we see the same as we do with the proposed model (4), which is the corpus (full set of documents in the index), leading to the documents, leading to the terms.
This illustrates the actual hierarchy into the system, but you can casually think of it in reverse, from the top down. We have terms. We look for documents with those terms. Those documents are in the corpus of all the documents we know about.
To the lower left (1) in the standard Information Retrieval (IR) architecture, you’ll notice that there is no BERT layer. The query used in their illustration (nike running shoes) enters the system, and the weights are computed independently of the model and passed to it.
In the illustration here, the weights are passing equally among the three words in the query. However, it does not have to be that way. It’s simply a default and good illustration.
What is important to understand is that the weights are assigned from outside the model and entered it with the query. We’ll cover why this is important momentarily.
If we look at the term-weight version on the right side, you’ll see that the query “nike running shoes” enters BERT (Term Weighting BERT, or TW-BERT, to be specific) which is used to assign the weights that would be best applied to that query.
From there things follow a similar path for both, a scoring function is applied and documents are ranked. But there’s a key final step with the new model, that is really the point of it all, the ranking loss calculation.
This calculation, which I was referring to above, makes the weights being determined within the model so important. To understand this best, let’s take a quick aside to discuss loss functions, which is important to really understand what’s going on here.
What is a loss function?
In machine learning, a loss function is basically a calculation of how wrong a system is with said system trying to learn to get as close to a zero loss as possible.
Let’s take for example a model designed to determine house prices. If you entered in all the stats of your house and it came up with a value of $250,000, but your house sold for $260,000 the difference would be considered the loss (which is an absolute value).
Across a large number of examples, the model is taught to minimize the loss by assigning different weights to the parameters it is given until it gets the best result. A parameter, in this case, may include things like square feet, bedrooms, yard size, proximity to a school, etc.
Now, back to query term weighting
Looking back at the two examples above, what we need to focus on is the presence of a BERT model to provide the weighting to the terms down-funnel of the ranking loss calculation.
To put it differently, in the traditional models, the weighting of the terms was done independent of the model itself and thus, could not respond to how the overall model performed. It could not learn how to improve in the weightings.
In the proposed system, this changes. The weighting is done from within the model itself and thus, as the model seeks to improve it’s performance and reduce the loss function, it has these extra dials to turn bringing term weighting into the equation. Literally.
ngrams
TW-BERT isn’t designed to operate in terms of words, but rather ngrams.
The authors of the paper illustrate well why they use ngrams instead of words when they point out that in the query “nike running shoes” if you simply weight the words then a page with mentions of the words nike, running and shoes could rank well even if it’s discussing “nike running socks” and “skate shoes”.
Traditional IR methods use query statistics and document statistics, and may surface pages with this or similar issues. Past attempts to address this focused on co-occurrence and ordering.
In this model, the ngrams are weighted as words were in our previous example, so we end up with something like:

On the left we see how the query would be weighted as uni-grams (1-word ngrams) and on the right, bi-grams (2-word ngrams).
The system, because the weighting is built into it, can train on all the permutations to determine the best ngrams and also the appropriate weight for each, as opposed to relying only on statistics like frequency.
Zero shot
An important feature of this model is its performance in zero-short tasks. The authors tested in on:
- MS MARCO dataset – Microsoft dataset for document and passage ranking
- TREC-COVID dataset – COVID articles and studies
- Robust04 – News articles
- Common Core – Educational articles and blog posts
They only had a small number of evaluation queries and used none for fine-tuning, making this a zero-shot test in that the model was not trained to rank documents on these domains specifically. The results were:

It outperformed in most tasks and performed best on shorter queries (1 to 10 words).
And it’s plug-and-play!
OK, that might be over-simplifying, but the authors write:
“Aligning TW-BERT with search engine scorers minimizes the changes needed to integrate it into existing production applications, whereas existing deep learning based search methods would require further infrastructure optimization and hardware requirements. The learned weights can be easily utilized by standard lexical retrievers and by other retrieval techniques such as query expansion.”
Because TW-BERT is designed to integrate into the current system, integration is far simpler and cheaper than other options.
What this all means for you
With machine learning models, it’s difficult to predict example what you as an SEO can do about it (apart from visible deployments like Bard or ChatGPT).
A permutation of this model will undoubtedly be deployed due to its improvements and ease of deployment (assuming the statements are accurate).
That said, this is a quality-of-life improvement at Google, that will improve rankings and zero-shot results with a low cost.
All we can really rely on is that if implemented, better results will more reliably surface. And that’s good news for SEO professionals.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.



