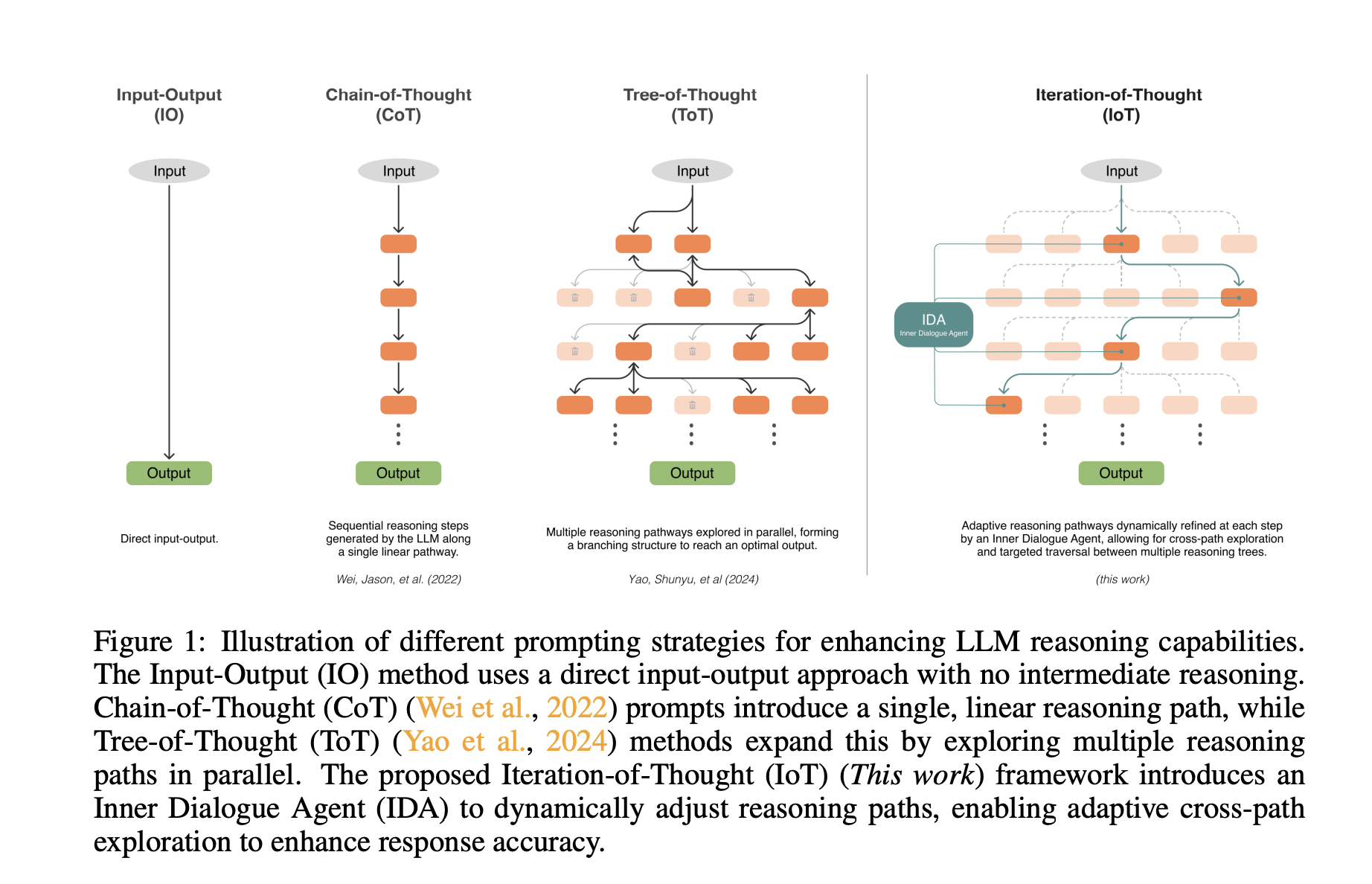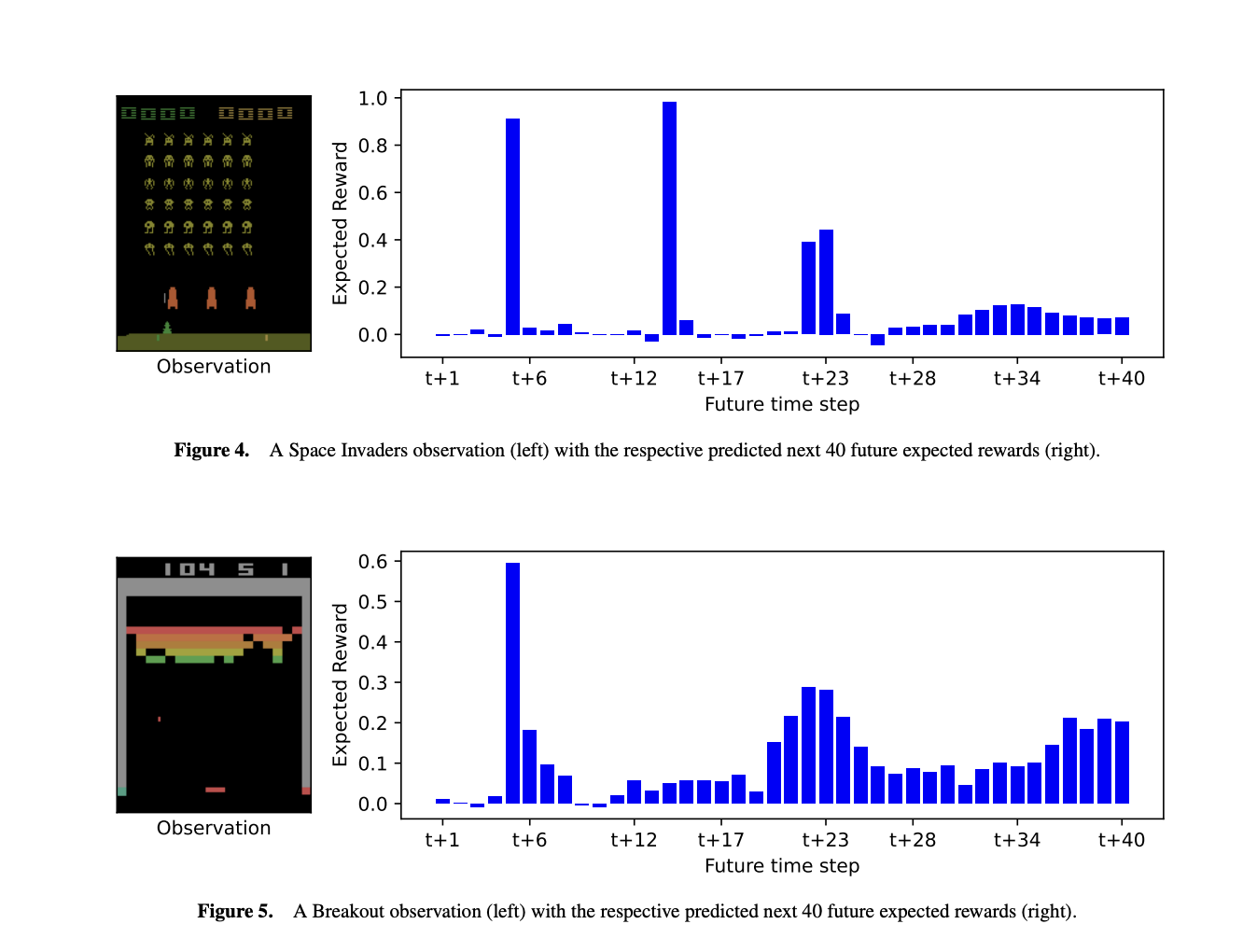
Future reward estimation is crucial in RL as it predicts the cumulative rewards an agent might receive, typically through Q-value or state-value functions. However, these scalar outputs lack detail about when or what specific rewards the agent anticipates. This limitation is significant in applications where human collaboration and explainability are essential. For instance, in a scenario where a drone must choose between two paths with different rewards, the Q-values alone do not reveal the nature of the rewards, which is vital for understanding the agent’s decision-making process.
Researchers from the University of Southampton and Kings College London introduced Temporal Reward Decomposition (TRD) to enhance explainability in reinforcement learning. TRD modifies an agent’s future reward estimator to predict the next N expected rewards, revealing when and what rewards are anticipated. This approach allows for better interpretation of an agent’s decisions, explaining the timing and value of expected rewards and the influence of different actions. With minimal performance impact, TRD can be integrated into existing RL models, such as DQN agents, offering valuable insights into agent behavior and decision-making in complex environments.
The study focuses on existing methods for explaining RL agents’ decision-making based on rewards. Previous work has explored decomposing Q-values into reward components or future states. Some methods contrast reward sources, like coins and treasure chests, while others decompose Q-values by state importance or transition probabilities. However, these approaches need to address the timing of rewards and may not scale to complex environments. Alternatives like reward-shaping or saliency maps offer explanations but require environment modifications or focus on visual regions rather than specific rewards. TRD introduces an approach by decomposing Q-values over time, enabling new explanation techniques.
The study introduces essential concepts for understanding the TRD framework. It begins with Markov Decision Processes (MDPs), a foundation of reinforcement learning that models environments with states, actions, rewards, and transitions. Deep Q-learning is then discussed, highlighting its use of neural networks to approximate Q-values in complex environments. QDagger is introduced to reduce training time by distilling knowledge from a teacher agent. Lastly, GradCAM is explained as a tool for visualizing which features influence neural network decisions, providing interpretability for model outputs. These concepts are foundational for understanding TRD’s approach.
The study introduces three methods for explaining an agent’s future rewards and decision-making in reinforcement learning environments. First, it describes how TRD predicts when and what rewards an agent expects, helping to understand agent behavior in complex settings like Atari games. Second, it uses GradCAM to visualize which features of an observation influence predictions of near-term versus long-term rewards. Lastly, it employs contrastive explanations to compare the impact of different actions on future rewards, highlighting how immediate versus delayed rewards affect decision-making. These methods offer new insights into agent behavior and decision-making processes.
AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI
In conclusion, TRD enhances understanding of reinforcement learning agents by providing detailed insights into future rewards. TRD can be integrated into pretrained Atari agents with minimal performance loss. It offers three key explanatory tools: predicting future rewards and the agent’s confidence in them, identifying how feature importance shifts with reward timing, and comparing the effects of different actions on future rewards. TRD reveals more granular details about an agent’s behavior, such as reward timing and confidence, and can be expanded with additional decomposition approaches or probability distributions for future research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.