If you’re reading this, you’ve likely encountered the “Crawled – Currently Not Indexed” error in Google Search Console.
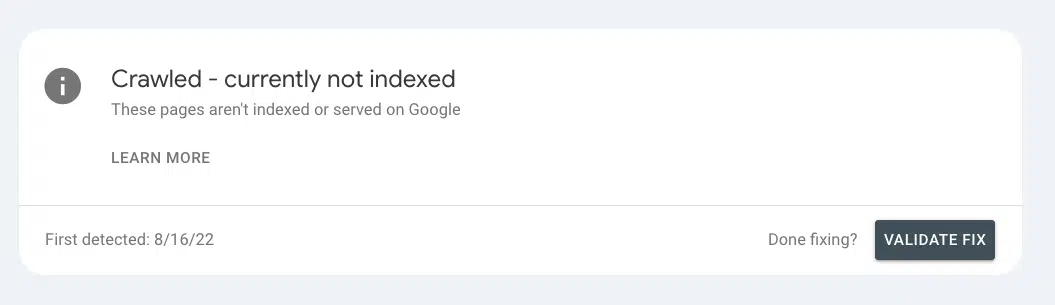
Of the 213 Google Search Console profiles I access, 89% have the “Crawled – Currently Not Indexed” error listed in their Google Search Console accounts. (Yes, I counted).
As any SEO professional will tell you, it can feel like the end of the world when you don’t know how to solve the error, resulting in a shriveled backlog of technical errors you’ll get to one day.
Before you toss this error in the pile to review later, take a step back and assess the data. I’ve rounded up seven fixes for the most common SEO debacles I’ve seen so you can salvage your websites and save a little time.
Why would Google crawl a page but not index it?
There are several reasons why a page may be crawled but not indexed.
In Google’s SEO Office Hours in March 2022, John Mueller highlighted some of the common reasons why users may see the error “Crawled – Currently not indexed,” like:
- Error code like a 404 error.
- Noindex tag on the page.
- Duplicate content.
Mueller later stated another reason:
- “We crawl something, but by the time we get to indexing, we decide we actually want to get something else from the website instead.”
If you read between the lines, I interpreted this as Google classifying your content as unhelpful, signaling a quality issue.
With Google’s AI Overview announcement, Google is reducing the crawl budget, so optimizing your crawl budget with quality content is a high priority.
This ties into what Gary Illyes mentioned on X, where your poor-quality content is replaced with higher-quality content.
How do I fix ‘Crawled – Currently not indexed’ in Google Search Console?
1. Manually review all the pages flagged in the report
First, I manually reviewed all the pages flagged in the Google Search Console “Crawled – currently not indexed” report.
To access the report, go to Google Search Console > Pages, then look under the section “Why pages aren’t indexed.”
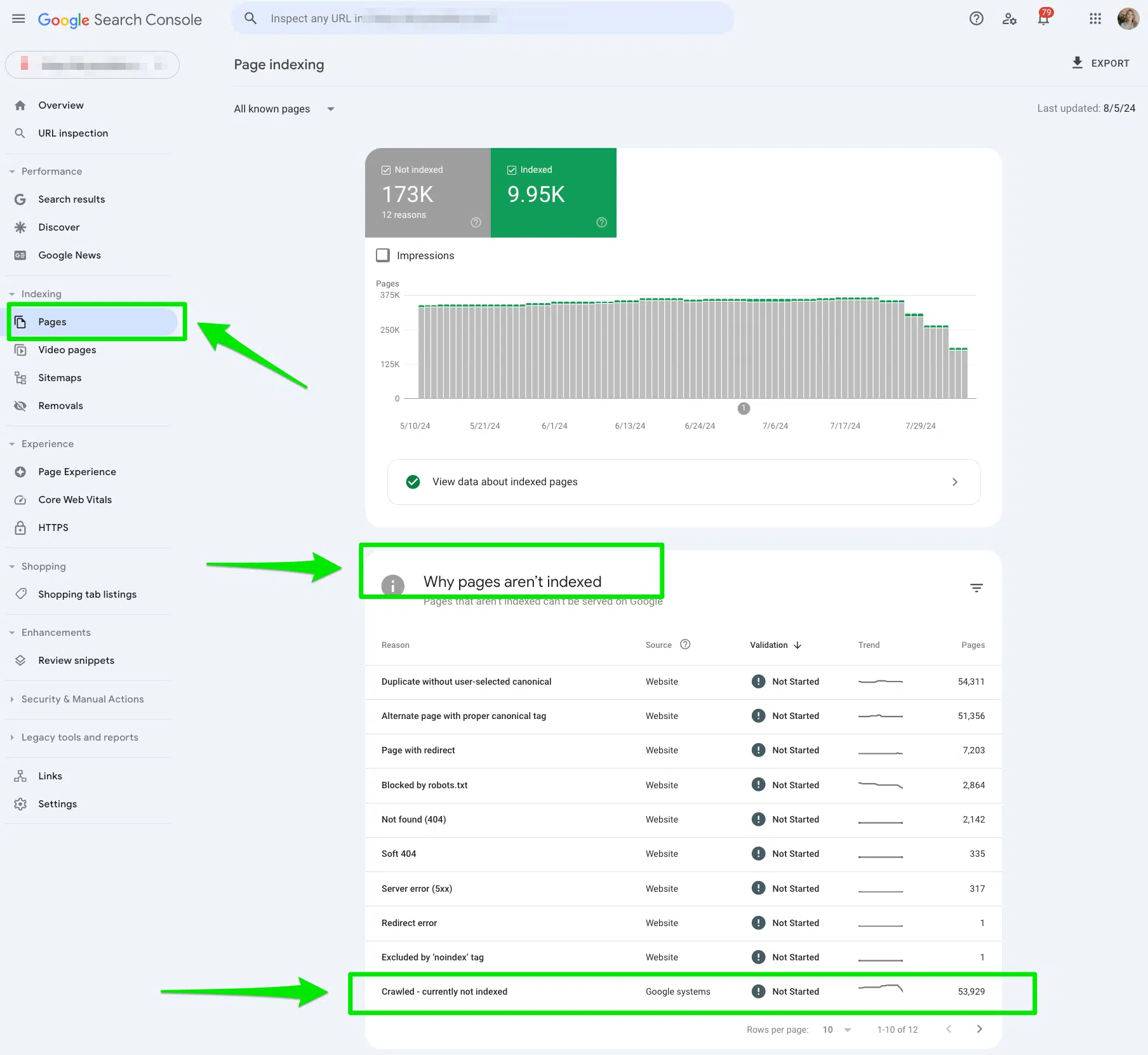
Once in the report, you can export the data to Google Sheets, Excel, or CSV to filter it.
Then, there are two things I start to dive into:
- Dates compared to affected pages: I’m looking to see if the trend line is growing or decreasing. If it’s reducing, it signals that we may have fixed the issue.
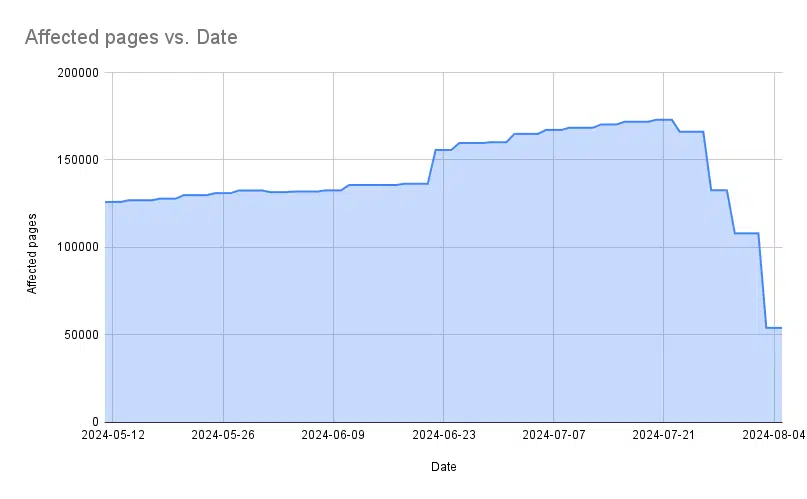
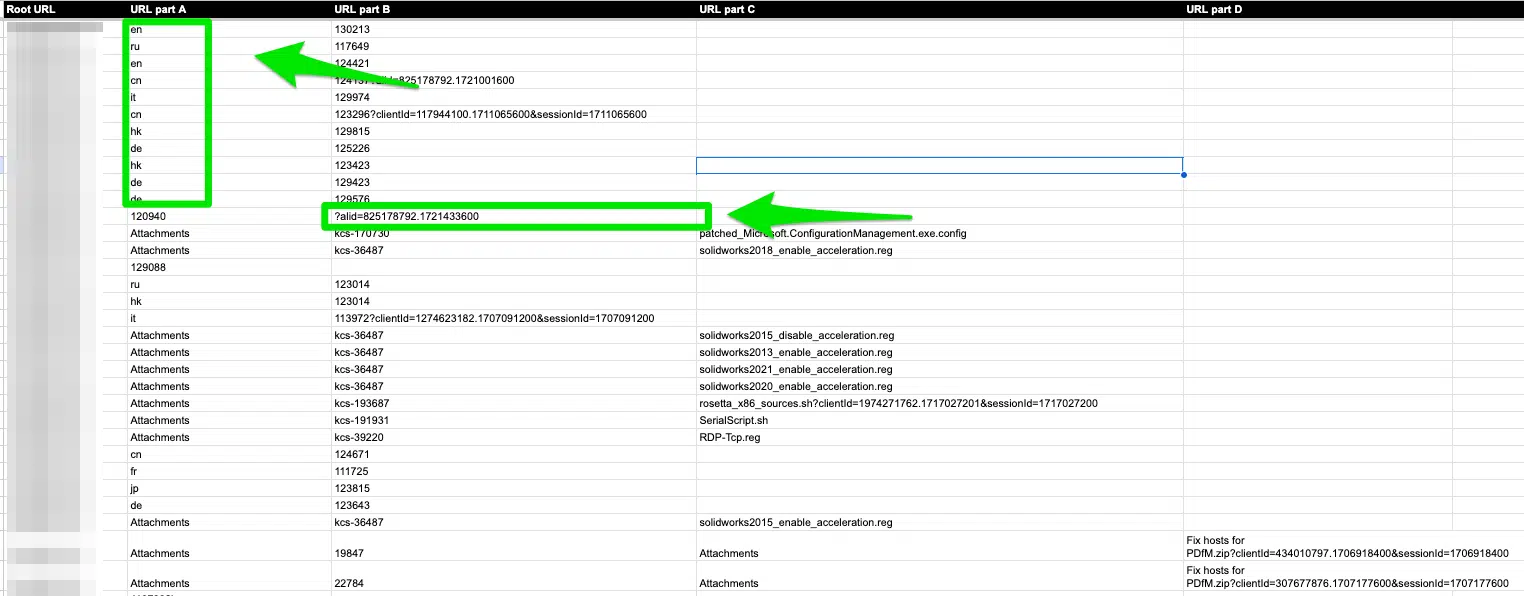
- URL structure: I’m looking to see if there’s a typical pattern between parameter URLs, language subfolders, or similar URLs. I use the “Split text to columns” option in Google Sheets. This helps me identify patterns. As you can see below, I already know I need to investigate two potential issues: international SEO and canonical tags.
2. Start an internal link hierarchy implementation project
If you’ve ever launched a piece of content without an internal link, or just plain forgot (ahem), you’ve probably asked yourself why your content isn’t performing.
When you spend hours, days, and sometimes months prepping a golden nugget of content only to see it as a sad, broken mess with no traffic, it’s not fun.
Fortunately, if there are ways to salvage the content and make it a higher quality piece, Google is ready to index.
All you need is a little internal link hierarchy implementation project.
I take at least two weeks to map out internal link opportunities by identifying internal pages to link from and to.
To find quality internal link chances, I leverage Google’s site search operators like “Site:mydomain.com Keyword.”
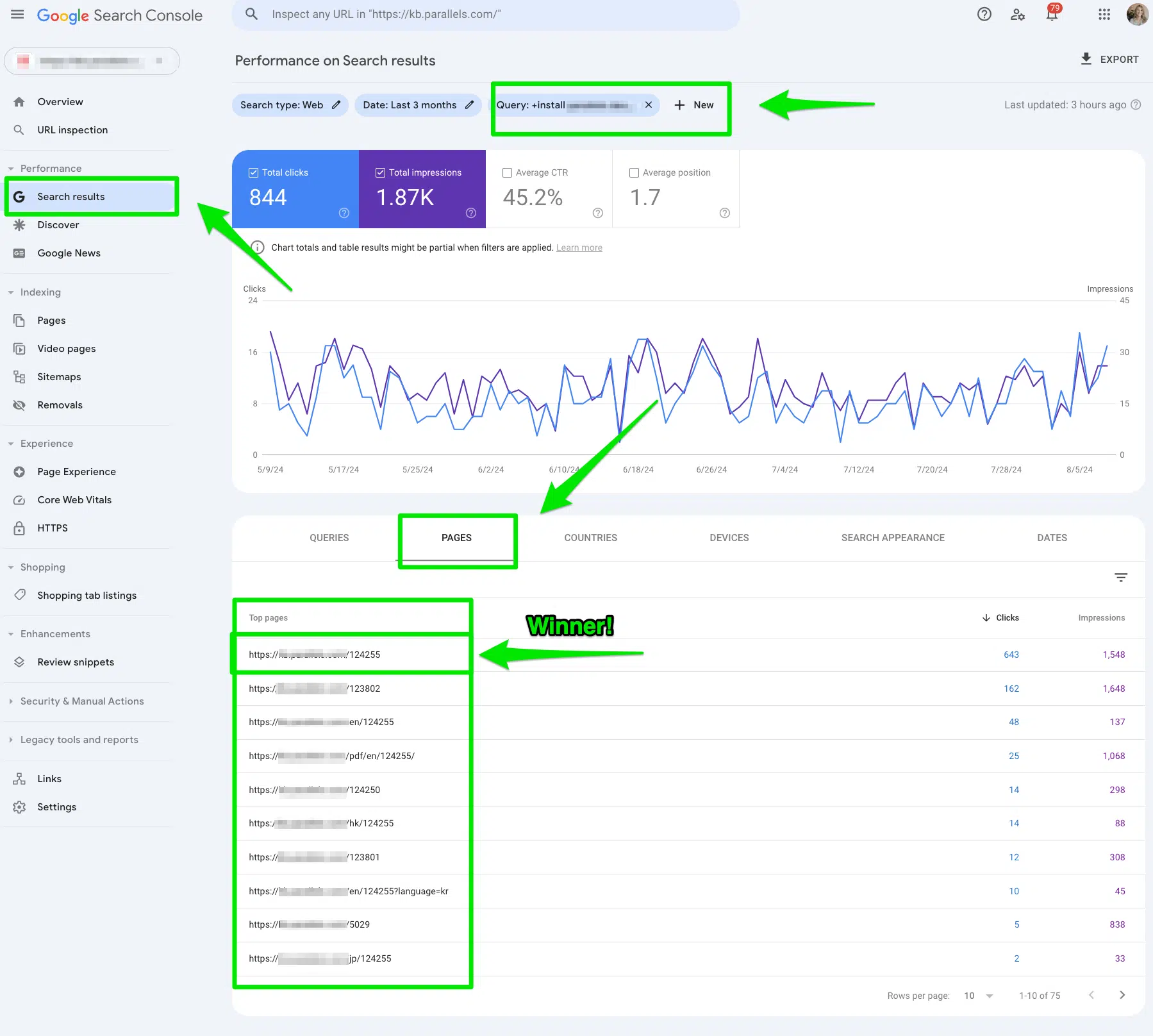
Once I gather a list of 5-10 pages I’d like to link to and from, I check for keyword cannibalization in Google Search Console.
Go to Search Results > type of your Query > filter by pages in Google Search Console.
Then, I pick the page that I want to rank for these terms as my primary internal link.
Remember your website’s structure. If there are many pages not listed in the navigation, search engines may not find them because of your site structure.
3. Add self-referencing canonical tags to combat duplicate content
The next battle I aim to win is removing any duplicate content in the report.
Add self-referencing canonical tags to parameter URLs to avoid duplicate content.
For example, let’s say this URL was listed in my report for “Crawled – Currently not indexed”:
- www.annalovesburritos.com/en/120313
The canonical tag should be self-referencing and look like this:
- www.annalovesburritos.com/en/120313
But sometimes, I run into issues where the canonical tag looks like this
- www.annalovesburritos.com/120313
See anything missing? The subfolder is missing.
Another challenge I face is when the canonical tag for a parameter URL is listed.
Let’s use the example above:
- www.annalovesburritos.com/en/120313
And we add a parameter:
- www.annalovesburritos.com/en/120313?clientID-12345
But when you check the canonical tag, it shows the parameter URL:
- www.annalovesburritos.com/en/120313?clientID-12345
You do not want to list your parameter URL as your canonical tag to avoid duplicate content.
So, if you see this:
You’ll want to change it to this:
5. Double-check your hreflang tags are correct
Another quick win to help get your content crawled and indexed is double-checking your hreflang tags.
You’ll want to ensure your country and language codes are accurate.
But you’ll also want to check that the content exists in the language it says it does.
I can’t tell you how many times I’ve come across hreflang that says it’s in Japanese, but when I actually go to the Japanese web page, it’s written in English.
This is considered duplicate content, and Google will likely never index it.
6. Audit your XML sitemap
Once you’ve cleaned up the canonical and hreflang tags, check your XML sitemap.
You want to ensure that all the pages listed in your XML sitemap are 200 status pages with self-referencing canonical tags and localized versions listed under the primary version.
If you have key money pages, you can create a temporary XML sitemap that focuses only on the pages listed in the “Crawled–Currently not indexed” report.
7. Submit fixed URLs to the URL inspection tool
The final step is manually submitting all your fixed URLs into the URL inspection tool in Google Search Console.
Typically, I’ll choose batches of 10-20 URLs and see how Google treats those.
Keep in mind that just because you did everything right doesn’t mean Google will fix the issue. It becomes a waiting game for Google to recrawl each URL and determine if it’s better than an existing page.
Helpful content is the way to avoid the ‘Crawled – Currently not indexed’ error in Google Search Console
Let’s face it: Google likely is not indexing your content because of quality issues.
Remember, just because a page is indexed today does not guarantee it will be indexed tomorrow. Google will change how it evaluates content, and you must adapt to that change.
You are always monitoring your content and looking for ways to implement improvements.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.