Large Language Models (LLMs) have revolutionized natural language processing, enabling AI systems to perform a wide range of tasks with remarkable proficiency. However, researchers face significant challenges in optimizing LLM performance, particularly in human-LLM interactions. A critical observation reveals that the quality of LLM responses tends to improve with repeated prompting and user feedback. Current methodologies often rely on naïve prompting, leading to calibration errors and suboptimal results. This presents a crucial problem: developing more sophisticated prompting strategies that can significantly enhance the accuracy and reliability of LLM outputs, thereby maximizing their potential in various applications.
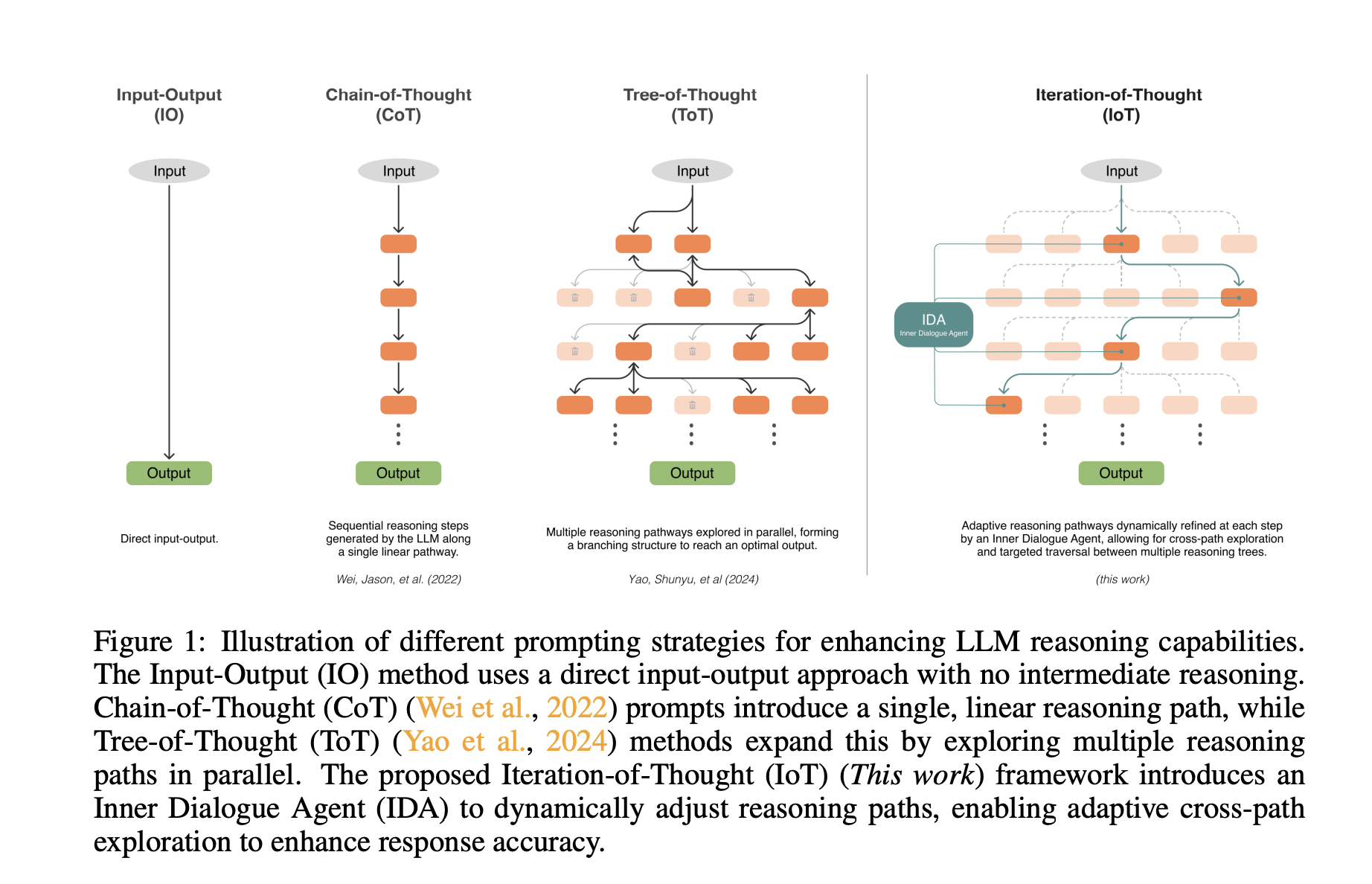
Researchers have attempted to overcome the challenges in optimizing LLM performance through various prompting strategies. The Input-Output (IO) method represents the most basic approach, using a direct input-output mechanism without intermediate reasoning. This method, however, often falls short in complex tasks requiring nuanced understanding. Chain-of-thought (CoT) prompting emerged as an advancement, introducing a single, linear reasoning path. This approach encourages LLMs to articulate intermediate reasoning steps, leading to improved performance on complex tasks. Building upon this, Tree-of-Thought (ToT) methods expanded the concept by exploring multiple reasoning paths in parallel, forming a branching structure to optimize outputs. This approach has shown particular efficacy in explorative tasks like puzzle-solving. Also, some other frameworks, such as Self-Refine and Self-Verification, enable LLMs to critique and refine their outputs iteratively. However, these methods still rely on static or semi-static prompts, limiting their adaptability to evolving contexts. Despite these advancements, current approaches struggle to fully utilize the LLM’s internal knowledge base and adapt dynamically to each unique query and response context.
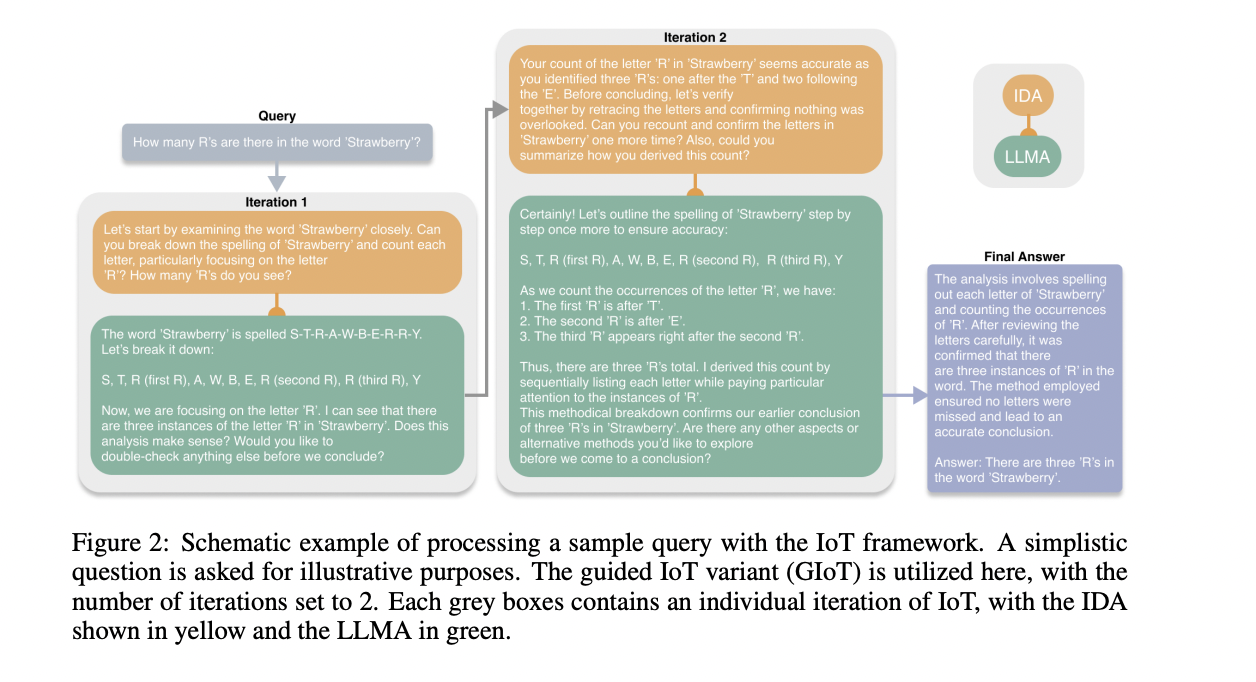
Researchers from Agnostiq Inc. and the University of Toronto introduce the Iteration of Thought (IoT) framework, an autonomous, iterative, and adaptive approach to LLM reasoning without human feedback. Unlike static and semi-static frameworks, IoT utilizes an Inner Dialogue Agent (IDA) to adjust and refine its reasoning path during each iteration. This enables adaptive exploration across different reasoning trees, fostering a more flexible and context-aware response generation process. Also, the core IoT framework consists of three main components: the IDA, the LLM Agent, and the Iterative Prompting Loop. The IDA functions as a guide, dynamically generating context-sensitive prompts based on the original user query and the LLM’s previous response. The LLMA embodies the core reasoning capabilities of an LLM, processing the IDA’s dynamically generated prompts. The Iterative Prompting Loop facilitates a back-and-forth interaction between the IDA and LLMA, continuously improving the quality of answers without external inputs.
LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK LINK
The IoT framework is implemented through two variants: Autonomous Iteration of Thought (AIoT) and Guided Iteration of Thought (GIoT). AIoT allows the LLM Agent to autonomously decide when it has generated a satisfactory response, potentially leading to faster evaluation but risking premature stops on complex queries. GIoT mandates a fixed number of iterations, aiming for a comprehensive exploration of reasoning paths at the cost of additional computational resources. Both variants utilize the core IoT components: the Inner Dialogue Agent, LLM Agent, and Iterative Prompting Loop. Implemented as a Python library with Pydantic for output schemas, IoT enables adaptive exploration across different reasoning trees. The choice between AIoT and GIoT allows for balancing exploration depth and computational efficiency based on task requirements.
The IoT framework demonstrates significant improvements across various reasoning tasks. On the GPQA Diamond dataset, AIoT achieved a 14.11% accuracy improvement over the baseline Input-Output method, outperforming CoT and GIoT. For exploratory problem-solving tasks like Game of 24 and Mini Crosswords, GIoT showed superior performance, with improvements of 266.4% and 90.6% respectively over CoT. In multi-context reasoning tasks using the HotpotQA-Hard dataset, AIoT outperformed CoT and even surpassed the AgentLite framework, achieving a higher F1 of 0.699 and an Exact Match of 0.53 scores. These results highlight IoT’s effectiveness in adapting to different reasoning contexts, from deep knowledge tasks to multi-hop question answering, showcasing its potential as a versatile and powerful reasoning framework for large language models.
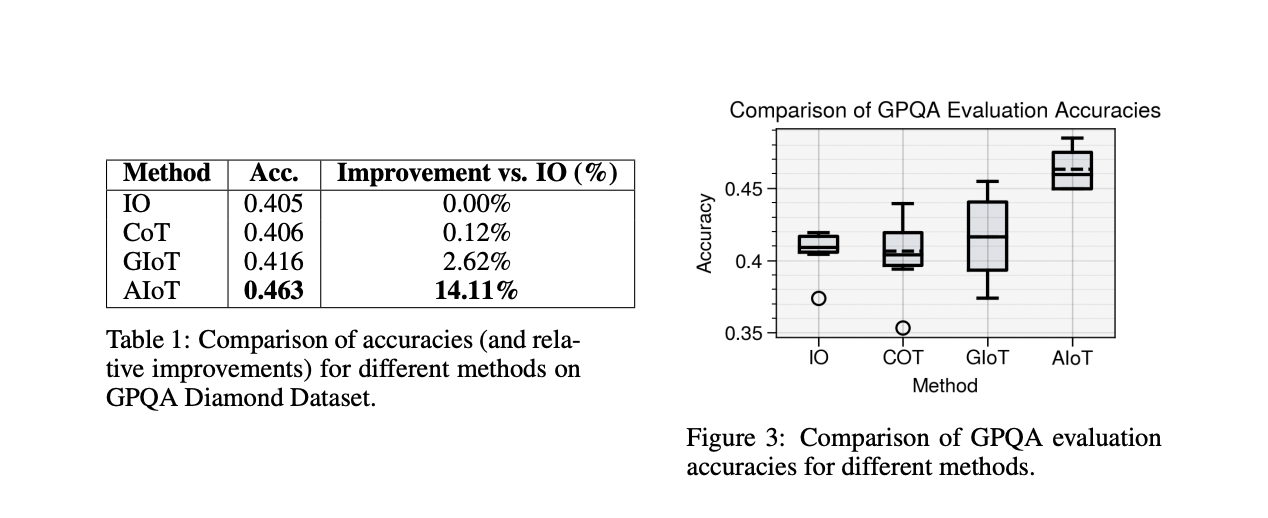
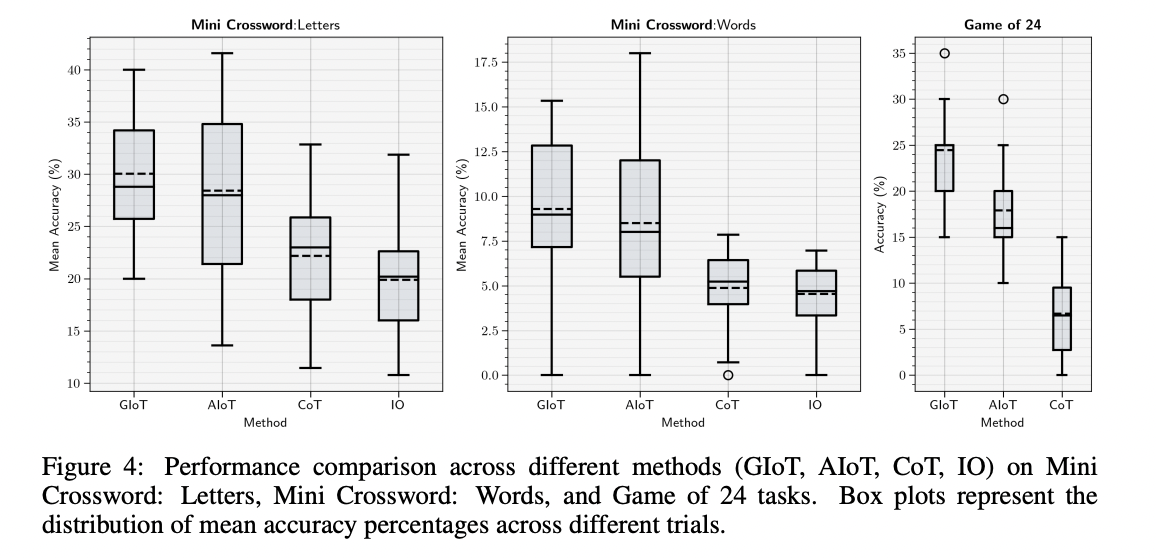
The IoT framework introduces a unique approach to complex reasoning tasks using large language models. IoT demonstrates significant improvements across various challenging tasks by employing an IIDA that iteratively converses with an LLM Agent. Two variants of the framework, AIoT, and GIoT, were tested on diverse problems including puzzles (Game of 24, Mini Crosswords) and complex questionnaires (GPQA, HotpotQA). GIoT, which performs a fixed number of iterations, excelled in the Game of 24, while AIoT, with its self-determined termination, showed superior performance on GPQA. Both variants outperformed the CoT framework in all compared tasks. Particularly, on the multi-context HotpotQA task, IoT surpassed the hierarchical AgentLite framework, achieving approximately 35% improvement in the F1 score and 44% in the Exact Match score. These results underscore IoT’s ability to introduce productive dynamism into low-complexity agentic frameworks, marking a significant advancement in LLM reasoning capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.