In the realm of human-computer interaction (HCI), dialogue stands out as the most natural form of communication. The advent of speech language models (SLMs) has significantly enhanced speech-based conversational AI, yet these models remain constrained to turn-based interactions, limiting their applicability in real-time scenarios. This gap in real-time interaction presents a significant challenge, particularly in situations requiring immediate feedback and dynamic conversational flow. The inability to handle interruptions and maintain seamless interaction has spurred researchers to explore full duplex modeling (FDM) in interactive speech language models (iSLM). Addressing this challenge, the research introduces the Listening-while-Speaking Language Model (LSLM), an innovative design to enable real-time, uninterrupted interaction by integrating listening and speaking capabilities within a single system.
Current methods in speech-language models typically involve turn-based systems, where listening and speaking occur in isolated phases. These systems often employ separate automatic speech recognition (ASR) and text-to-speech (TTS) modules, leading to latency issues and an inability to handle real-time interruptions effectively. Notable models like SpeechGPT and LauraGPT have advanced conversational AI. Yet, they remain limited to these turn-based paradigms, unable to provide the fluid interaction required for more natural human-computer dialogue.
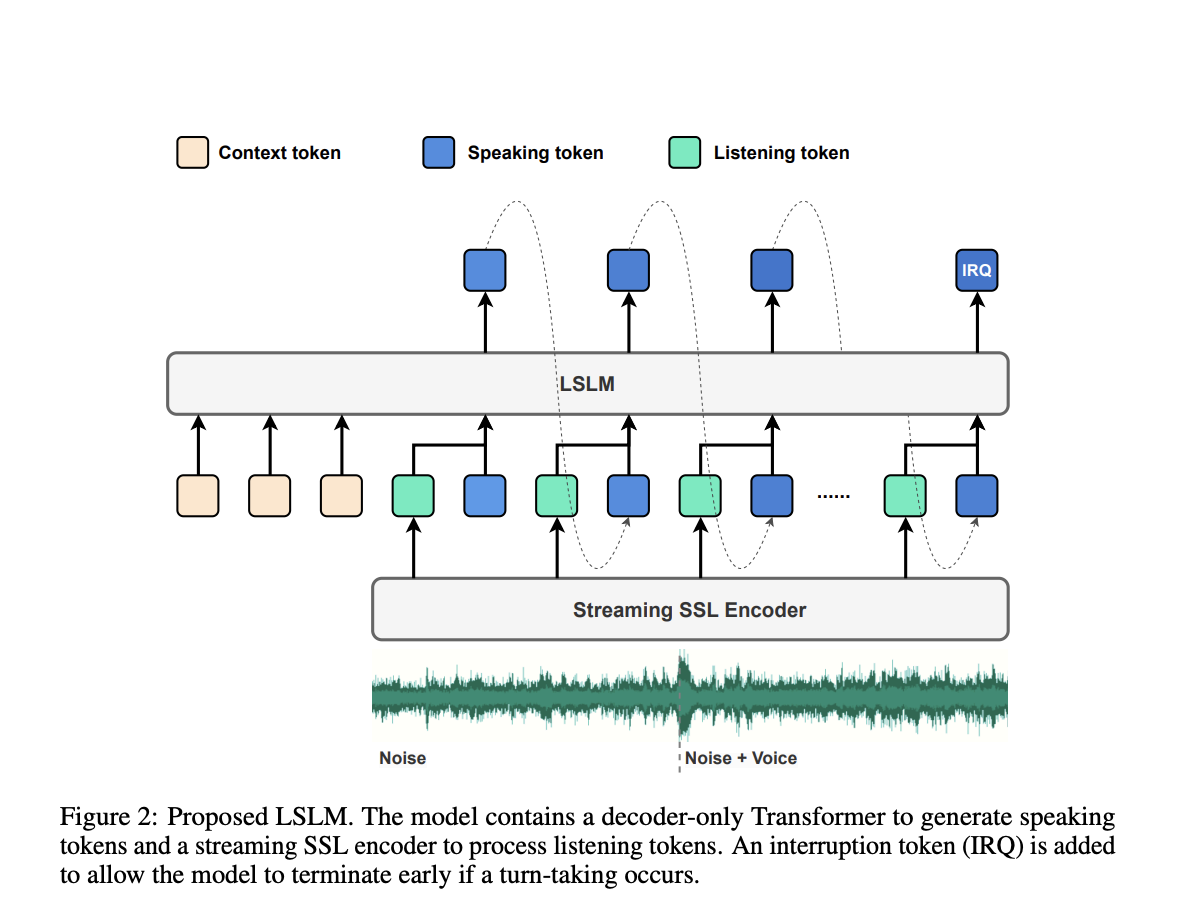
To overcome these limitations, a team of researchers from Shanghai Jiao Tong University and ByeDance propose the LSLM, an end-to-end system designed to simultaneously perform both listening and speaking. This model employs a token-based decoder-only TTS for speech generation and a streaming self-supervised learning (SSL) encoder for real-time audio input. The LSLM’s unique approach lies in its ability to fuse these channels, enabling it to detect real-time turn-taking and respond dynamically. By exploring three fusion strategies—early fusion, middle fusion, and late fusion—the researchers identified middle fusion as the optimal balance between speech generation and real-time interaction capabilities.
The LSLM’s architecture revolves around its dual-channel design. For speaking the model utilizes an autoregressive token-based TTS system. Unlike previous models that rely on autoregressive and non-autoregressive approaches, the LSLM simplifies this by using discrete audio tokens, enhancing real-time interaction, and eliminating the need for extensive processing before speech synthesis. The speaking channel generates speech tokens based on the given context with a vocoder, which converts these tokens into audible speech. This setup allows the model to focus more on semantic information, improving the clarity and relevance of its responses.
On the listening side, the model employs a streaming SSL encoder to process incoming audio signals continuously. This encoder converts audio input into continuous embeddings and then projects it into a space that can be processed alongside the speaking tokens. These channels are integrated through one of three fusion methods, with middle fusion emerging as the most effective. In this method, the listening and speaking channels are merged at each Transformer block, allowing the model to leverage both channels’ information throughout the speech generation process. This fusion strategy ensures the LSLM can handle interruptions smoothly and maintain a coherent and responsive dialogue flow.
Performance evaluation of the LSLM was conducted under two experimental settings: command-based FDM and voice-based FDM. In the command-based scenario, the model was tested on its ability to respond to specific commands amidst background noise. In contrast, the voice-based scenario evaluated its sensitivity to interruptions from various speakers. The results demonstrated the LSLM’s robustness to noisy environments and ability to recognize and adapt to new voices and instructions. The middle fusion strategy, in particular, balanced the demands of real-time interaction and speech generation, providing a seamless user experience.
The Listening-while-Speaking Language Model (LSLM) represents a significant leap forward in interactive speech-language models. By addressing the limitations of turn-based systems and introducing a robust, real-time interaction capability, the LSLM paves the way for more natural and fluid human-computer dialogues. The research highlights the importance of integrating full duplex capabilities into SLMs, showcasing how such advancements can enhance the applicability of conversational AI in real-world scenarios. Through its innovative design and impressive performance, the LSLM sets a new standard for future developments in speech-based HCI.
game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game game
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech at the Indian Institute of Technology (IIT), Bhubaneswar. An AI enthusiast, she enjoys staying updated on the latest advancements. Shreya is particularly interested in the real-life applications of cutting-edge technology, especially in the field of data science.