





Large Language Models have transformed Natural Language Processing by showcasing amazing skills like emergence and grokking and driving model size to increase continually. The bar for NLP research is raised by training these models with billions of parameters, such as those with 30B to 175B parameters. It is challenging for small labs and businesses to participate in this field of research since tuning LLMs frequently calls for expensive GPU resources, such as 880GB machines. Recently, resource-constrained LLM tuning has been made possible by parameter-efficient fine-tuning techniques such as LoRA and Prefix-tuning.
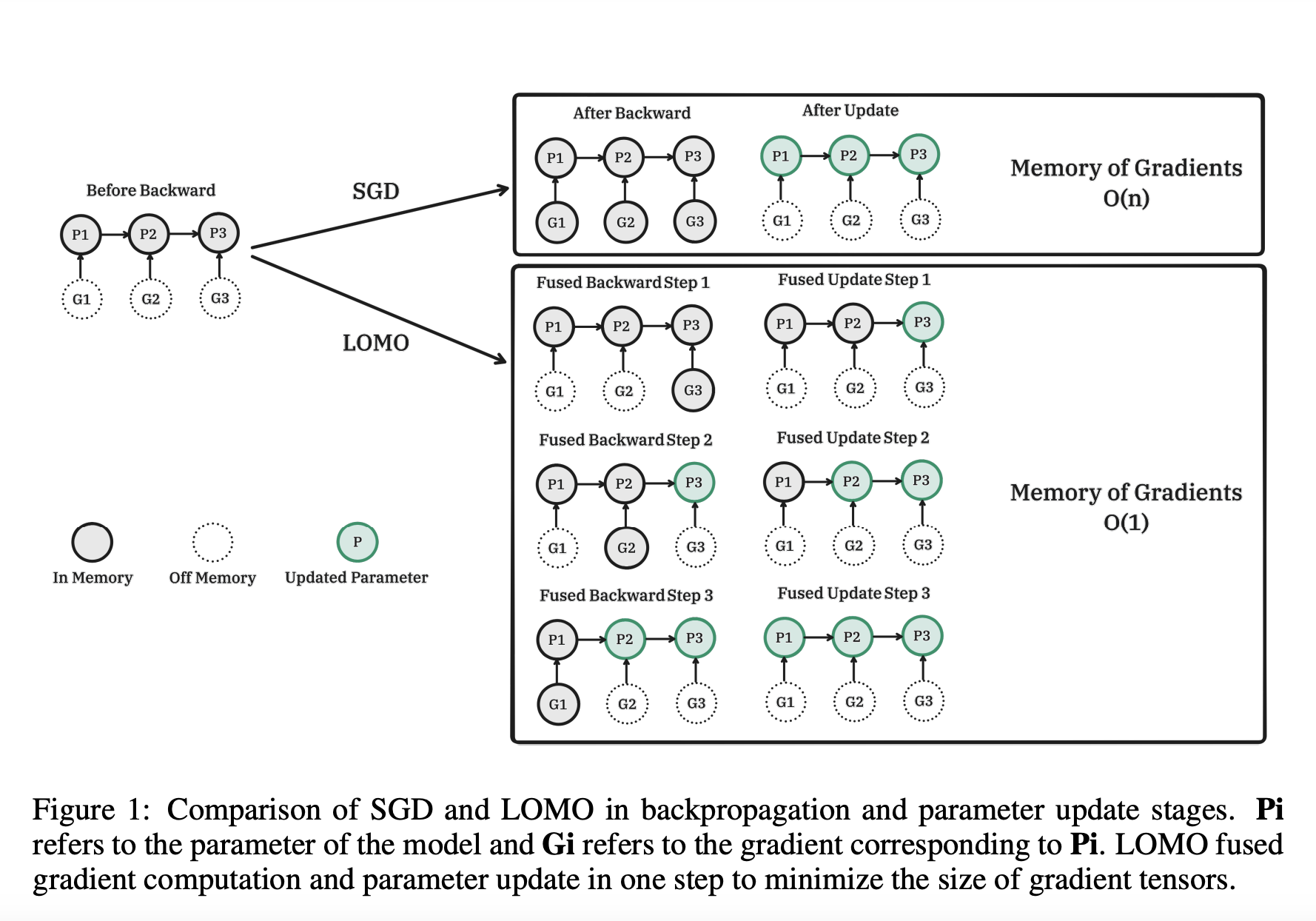
Although complete parameter fine-tuning has been regarded as a more effective strategy than parameter-efficient fine-tuning, both techniques must provide a workable solution. They want to investigate methods for completing comprehensive parameter fine-tuning in the circumstances with constrained resources. They examine activation, optimizer states, gradient tensor, and parameters—the four characteristics of memory utilization in LLMs—and optimize the training process in three ways: 1) They reevaluate the algorithmic functionality of an optimizer and discover that SGD is a suitable substitute for fine-tuning complete parameters for LLMs. Since SGD doesn’t maintain intermediate stages, we can delete the whole portion of optimizer states. 2) Their suggested optimizer, LOMO, as shown in Figure 1, decreases the memory use of gradient tensors to O, equal to the memory consumption of the greatest gradient tensor. 3) They incorporate gradient normalization and loss scaling and switch certain calculations to full precision during training to stabilize mix-precision training with LOMO. Their method combines the same amount of memory as parameters, activation, and the greatest gradient tensor.
They severely increase the memory consumption of complete parameter fine-tuning, reducing it to the level of inference. This is because the forward process alone shouldn’t require less memory than the backward process. Notably, they ensure the fine-tuning function is not impaired while using LOMO to conserve memory because the parameter update process is similar to SGD. Researchers from the Fudan University demonstrate how using LOMO makes it possible to successfully train a 65B model with only 8 RTX 3090 GPUs by empirically evaluating the memory and throughput capabilities of LOMO. Additionally, they use LOMO to adjust the entire parameters of LLMs on the SuperGLUE dataset collection to validate the downstream performance of their suggested approach. The empirical findings show how well LOMO performs while optimizing LLMs with many parameters.
These are their overall contributions:
• They offer a theoretical study that suggests SGD can successfully adjust all of the LLMs’ parameters. It’s possible that the obstacles that once prevented SGD from being widely used won’t be as serious when optimizing LLMs.
• They suggest LOMO, or low-memory optimization, to drastically reduce GPU memory utilization while maintaining the process of fine-tuning.
• They empirically demonstrate the efficiency of LOMO in optimizing LLMs in resource-constrained circumstances by carefully analyzing memory utilization and throughput performance. Performance assessments of downstream jobs provide additional justification for this.
The code implementation is available on GitHub.
Check Out the Paper and Github Link. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools:
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.



