




Despite only seeing the world in two dimensions, humans are adept at navigating, thinking, and interacting with their three-dimensional environment. This suggests a profoundly ingrained cognitive awareness of the traits and actions of the 3D environment, which is a great aspect of human nature. Artists who can create detailed 3D reproductions from a single photograph take this skill to a new level. Contrarily, after decades of research and advancement, the challenge of 3D reconstruction from an unposed image, including the production of geometry and textures, remains an open, ill-posed topic in computer vision. Many 3D creation activities may be learned-based thanks to recent deep learning advancements.
Although deep learning has made great progress in image identification and creation, it still needs to improve in the real world’s specific challenge of single-image 3D reconstruction. They place the blame for this significant gap between human and machine 3D reconstruction abilities on two main issues: (i) a lack of large-scale 3D datasets that prevents large-scale learning of 3D geometry, and (ii) the tradeoff between the level of detail and computational resources when working on 3D data. Utilizing 2D priors is one strategy to solve the issue. There is a vast amount of real 2D picture data online. To train cutting-edge image interpretation and generation algorithms like CLIP and Stable Diffusion, one of the most comprehensive datasets for text-image pairs is LAION.
There has been a noticeable increase in strategies that employ 2D models as priors for creating 3D material due to the expanding generalization capabilities of 2D generation models. DreamFusion pioneered this 2D prior-based technology for text-to-3D creation. The method shows a remarkable ability to direct unique views and enhance a neural radiance field (NeRF) in a zero-shot situation. Building on DreamFusion, recent research has attempted to adapt these 2D priors for single-picture 3D reconstructions using RealFusion and NeuralLift. A different strategy is to use 3D priors. In earlier efforts, 3D priors like topological restrictions were used to aid in 3D creation. These hand-made 3D priors can create some 3D stuff but could be better 3D content.
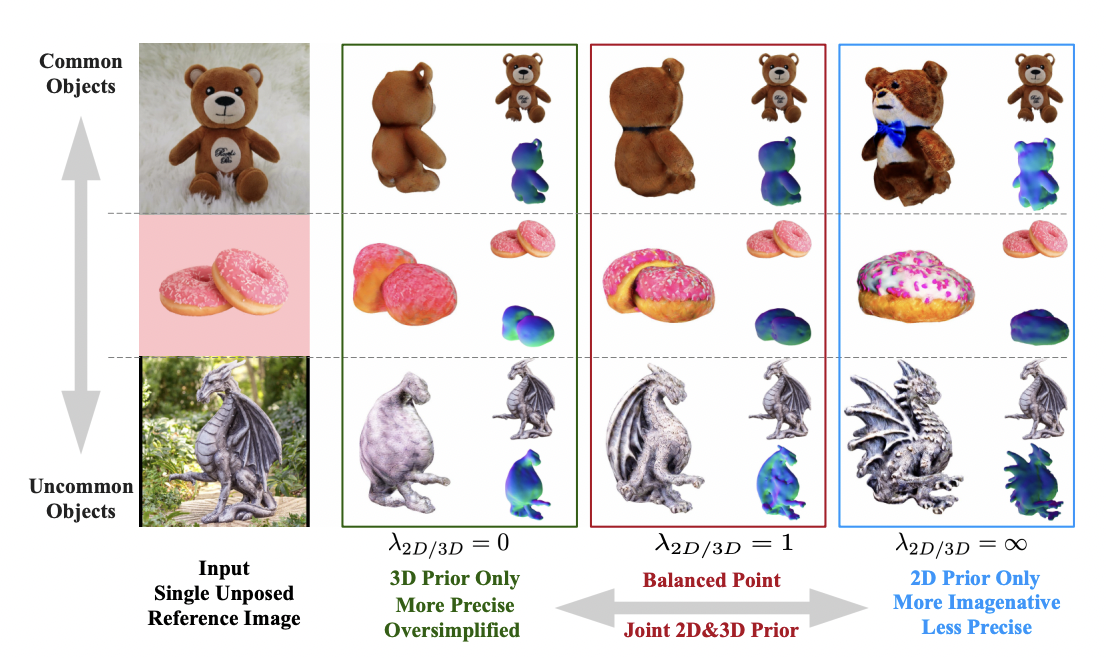
A 2D diffusion model was recently modified to become view-dependent, and this view-dependent diffusion was then used as a 3D prior in techniques like Zero-1-to-3 and 3Dim. According to their behavior analysis, both 2D and 3D priors have benefits and disadvantages. Compared to 3D priors, 2D priors have outstanding generalizations for 3D creation, as shown by the example of the dragon statue in Figure 1. Due to their limited 3D understanding, approaches solely depending on 2D priors ultimately suffer from losing 3D fidelity and consistency. Unrealistic geometry results from this, such as many faces (Janus issues), disparate sizes, uneven texture, etc. The example of the teddy bear in Figure 1 is a failure scenario.
However, because of the small amount of 3D training data, more than a severe dependence on 3D priors is needed for in-the-wild reconstruction. As a result, as shown in Fig. 1, although 3D prior-based solutions successfully handle common items (such as the teddy bear example in the top row), they struggle with less frequent things, producing too simplistic and occasionally even flat, 3D geometries (such as the dragon statue at the bottom left). Researchers from King Abdullah University of Science and Technology (KAUST), Snap Inc. and Visual Geometry Group, University of Oxford in this study promote the simultaneous use of both priors to direct innovative perspectives in image-to-3D creation rather than merely depending on a 2D or 3D prior. They may control the balance between exploration and exploitation in the resulting 3D geometry by varying the specific but useful tradeoff parameter between the potency of the 2D and 3D priors.
Figure 1 shows the trade-off between Magic123’s 2D and 3D priors. A teddy bear (a frequent item), two stacked donuts (a less common thing), and a dragon statue (an uncommon object) are the three scenarios for which they compare single-image reconstructions. As seen on the right, Magic123, which only has a 2D background, favours geometric exploration and creates 3D material with greater creativity but maybe with less consistency. With just 3D before, Magic123 (on the left) prioritises geometry exploitation, resulting in exact but maybe simpler geometry with less features.
Prioritizing the 2D previous can improve creative 3D skills to compensate for the partial 3D information in each 2D image. However, this could lead to less accurate 3D geometry because of a lack of 3D understanding. Prioritizing the 3D prior, on the other hand, can result in more 3D-constrained solutions and more accurate 3D geometry, but at the expense of lower creativity and a diminished capacity to find workable solutions for difficult and unusual circumstances. They present Magic123, a cutting-edge image-to-3D pipeline that produces high-quality 3D outputs using a two-stage coarse-to-fine optimization approach that uses both 2D and 3D priors.
They refine a neural radiance field (NeRF) in the coarse stage. NeRF effectively learns an implicit volume representation for learning complicated geometry. However, NeRF uses a lot of memory, which results in low-resolution generated pictures being sent to the diffusion models, which lowers the output quality for the image-to-3D process. Instant-NGP, a more resource-efficient NeRF substitute, is limited to an image-to-3D pipeline resolution of 128 128 on a 16GB memory GPU. As a result, they add a second step and use Deep Marching Tetrahedra (DMTet), a memory-efficient and texture-decomposed SDF-Mesh hybrid representation, to enhance the quality of the 3D content.
With the help of this method, they can separate the NeRF’s geometry and texture refinements and boost resolution to 1K. They use a mix of 2D and 3D priors in both phases to direct innovative perspectives. They offer the following summary of their contributions:
• They present Magic123, a revolutionary image-to-3D pipeline that creates high-quality, high-resolution 3D geometry and textures using a two-stage coarse-to-fine optimisation procedure.
• They suggest simultaneously using 2D and 3D priors to create accurate 3D content from any given image. Priors’ strength parameter enables a tradeoff between exploring and using geometry. Users may experiment with this tradeoff parameter to create the required 3D content.
• They can discover a balanced tradeoff between the 2D and 3D priors, resulting in 3D reconstructions that are relatively realistic and detailed. Magic123 produces state-of-the-art outcomes in 3D reconstruction from single unposed photos in real-world and synthetic contexts using the same set of parameters for all samples without further reconfiguring.
Check out the Paper and Project. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.



