




A group of researchers from Nvidia have developed a new technique called Tied-LoRA, which aims to improve the parameter efficiency of the Low-rank Adaptation (LoRA) method. The course uses weight tying and selective training to find the optimal balance between performance and trainable parameters. The researchers conducted experiments on different tasks and base language models and found that there are trade-offs between efficiency and performance.
Recent advances in parameter-efficient fine-tuning techniques include LoRA, which reduces trainable parameters through low-rank matrix approximations. AdaLoRA is an extension of LoRA that introduces dynamic rank adjustment and combines adapter tuning with LoRA. Another technique is VeRA, proposed by Kopiczko, which reduces parameters through frozen matrices and trainable scaling vectors. QLoRA uses quantized base models to achieve memory-efficient LoRA. This study applies weight tying to low-rank weight matrices, further enhancing parameter efficiency.
In addressing the computational expense of fine-tuning LLMs for downstream tasks, Tied-LoRA is a novel approach that combines weight tying and selective training to enhance the parameter efficiency of LoRA. It explores different parameter training/freezing and weight-tying combinations through systematic experiments on diverse studies and base language models. The researchers identify a specific Tied-LoRA configuration that achieves comparable performance while utilizing only 13% of the parameters compared to the standard LoRA method.
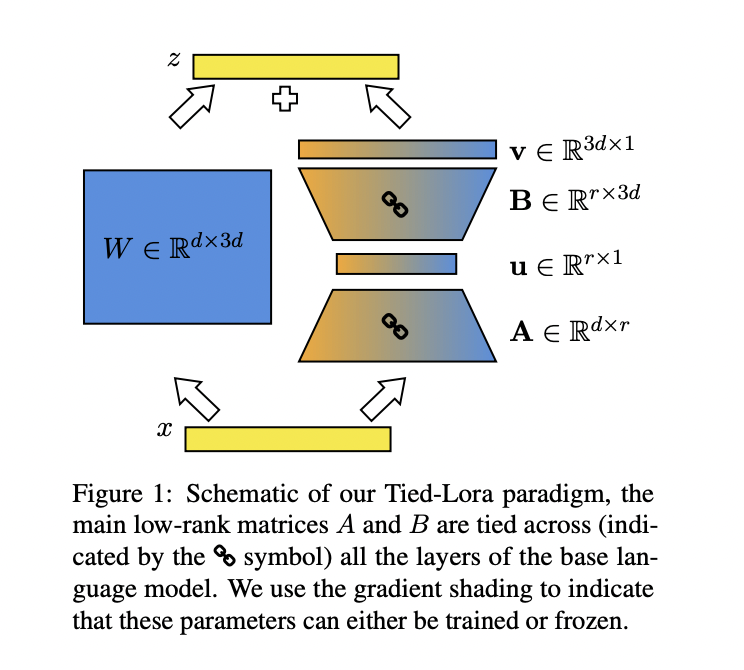
Tied-LoRA is a method that enhances the parameter efficiency of the LoRA approach by combining weight tying and selective training. It involves applying weight tying to low-rank matrices in LoRA, sharing the same consequences across layers in the base language model, thereby reducing the number of trainable parameters. It explores various combinations of parameter training/freezing and weight tying to achieve an optimal balance between performance and trainable parameters. The proposed Tied-LoRA configurations are evaluated on diverse tasks, demonstrating efficiency across data settings, including translation and mathematical reasoning.
In experiments across diverse tasks and two base language models, different Tied-LoRA configurations demonstrated trade-offs between efficiency and performance. A specific Tied-LoRA configuration, vBuA, outperformed others, achieving comparable performance. vBuA was identified as the optimal option, maintaining performance while reducing parameters by 87%. Evaluations on tasks like extractive question answering, summarization, and mathematical reasoning showcased Tied-LoRA’s ability to enhance parameter efficiency while preserving competitive performance significantly.
After conducting experiments across various tasks, it has been found that Tied-LoRA is a paradigm that enhances the parameter efficiency of the LoRA method by utilizing weight tying and selective training. The results suggest that Tied-LoRA can replace functions such as commonsense NLI, extractive QA, and summarization. Moreover, it offers improved parameter efficiency without compromising performance, utilizing only 13% of the parameters from standard LoRA. However, discussing limitations and comparisons with other parameter efficiency methods is important to identify potential areas for future exploration.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.



