




Thanks to artificial intelligence’s ongoing growth and development, large-scale language models are now widely available. Models like ChatGPT, GPT4, LLaMA, Falcon, Vicuna, and ChatGLM have shown outstanding performance in various traditional tasks, opening up a world of opportunity for the legal profession. However, gathering reliable, current, high-quality data is essential to creating sizable language models. Therefore, creating open-source legal language models that are both effective and efficient has become crucial.
Large-scale model development in artificial intelligence has impacted several industries, including healthcare, education, and finance: BloombergGPT, FinGPT, Huatuo, and ChatMed; these models have proven useful and effective in handling challenging problems and producing insightful data. On the other hand, the area of law demands thorough investigation and the creation of a unique legal model due to its intrinsic relevance and need for accuracy. Law is crucial in forming communities, regulating interpersonal relationships, and ensuring justice. Legal practitioners rely on accurate and current information to make wise judgments, understand the law, and offer legal advice.
The nuances of legal terminology, complicated interpretations, and the dynamic nature of law offer special problems that call for specialized solutions. Even with the most cutting-edge model, like GPT4, there is frequently a hallucination phenomenon and incredible results regarding legal difficulties. People often think improving a model with relevant domain expertise would provide positive outcomes. However, early legal LLM (LawGPT) still has a lot of hallucinations and inaccurate results, so this isn’t the case. At first, they understood the demand for a Chinese legal LLM. However, there were no Chinese models that were commercially accessible at the time that were larger than 13 billion parameters. Combining training data from sources like MOSS and increasing the Chinese lexicon improved the foundation of OpenLLAMA, an economically feasible model. This enabled researchers from Peking University to build a fundamental model of the Chinese language to which they then added legal-specific data to train ChatLaw, their legal model.
The following are the paper’s main contributions:
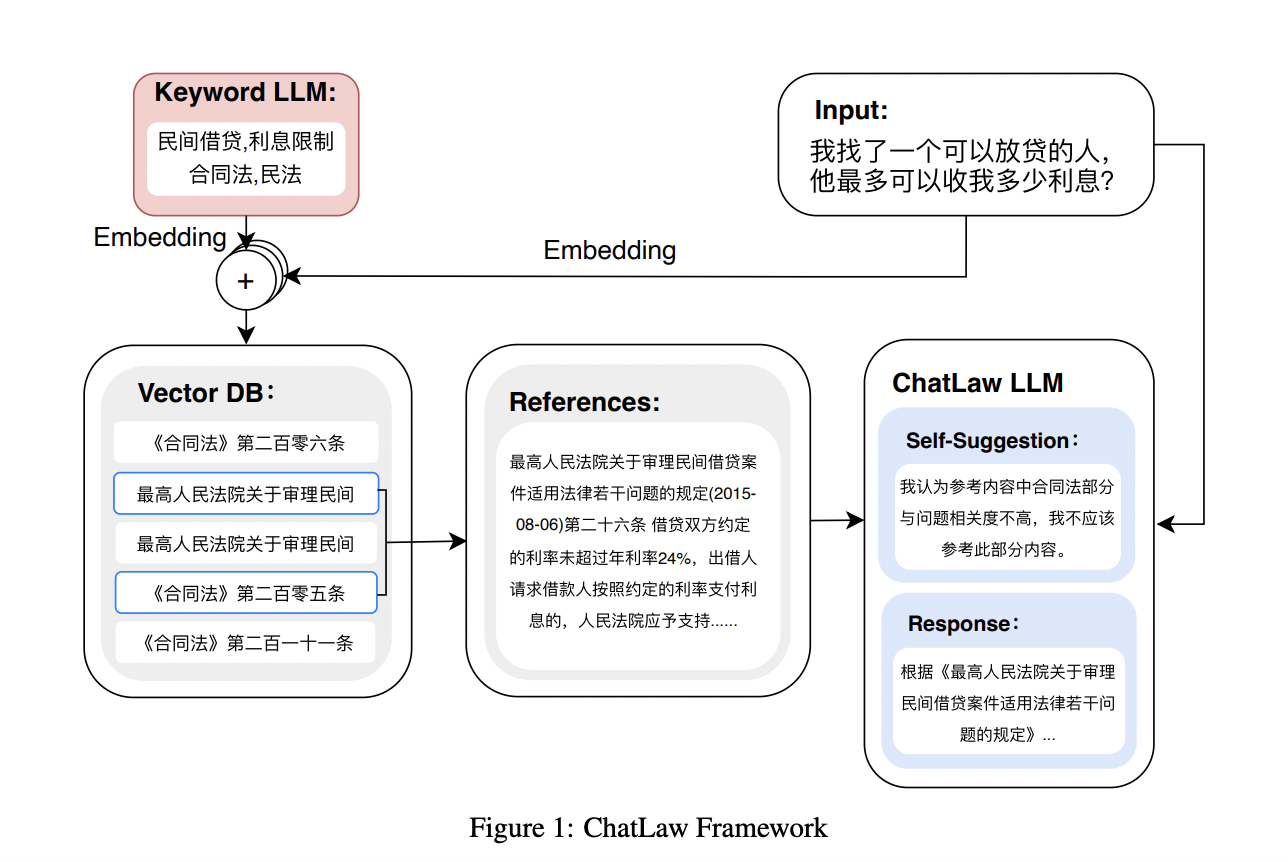
1. A Successful Method to Reduce Hallucinations: They present a method to reduce hallucinations by improving the model’s training procedure and including four modules during inference: “consult,” “reference,” “self-suggestion,” and “response.” Hallucinations are less frequent because vertical models and knowledge bases are integrated through the reference module, which incorporates domain-specific knowledge into the model and uses reliable data from the knowledge base.
2. A model that extracts legal feature words from users’ daily language has been trained. It is based on the LLM. With the help of this model, which recognizes terms with legal meaning, legal situations inside user input may be quickly and effectively identified and analyzed.
3. A model that measures the similarity between users’ ordinary language and a dataset of 930,000 pertinent court case texts is trained using BERT. This makes it possible to build a vector database to quickly retrieve writings with a similar legal context, allowing additional research and citation.
4. Development of a Chinese Legal Exam Assessing Dataset: They create a dataset to assess Chinese speakers’ legal expertise. They also make an ELO arena scoring system to determine how well various models perform in legal multiple-choice tests.
They also noted that a single general-purpose legal LLM might only function well in this area across some jobs. As a result, they developed numerous models for various situations, including multiple-choice questions, keyword extraction, and question-answering. Using the HuggingGPT technique, they used a large LLM as a controller to manage the selection and deployment of these models. Based on each user’s request, this controller model dynamically chooses the specific model to activate, ensuring the best model is used for the task.
Check out the Paper and Github Link. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.



