




Human scientists can explore the depths of the unknown and make discoveries requiring various undetermined choices. Armed with the body of scientific knowledge at their disposal, human researchers explore uncharted territories and make ground-breaking discoveries in the process. Studies now investigate if building AI research agents with similar capabilities is possible.
Open-ended decision-making and free interaction with the environment provide difficulties for performance evaluation, as these processes may be time-consuming, resource-intensive, and difficult to quantify.
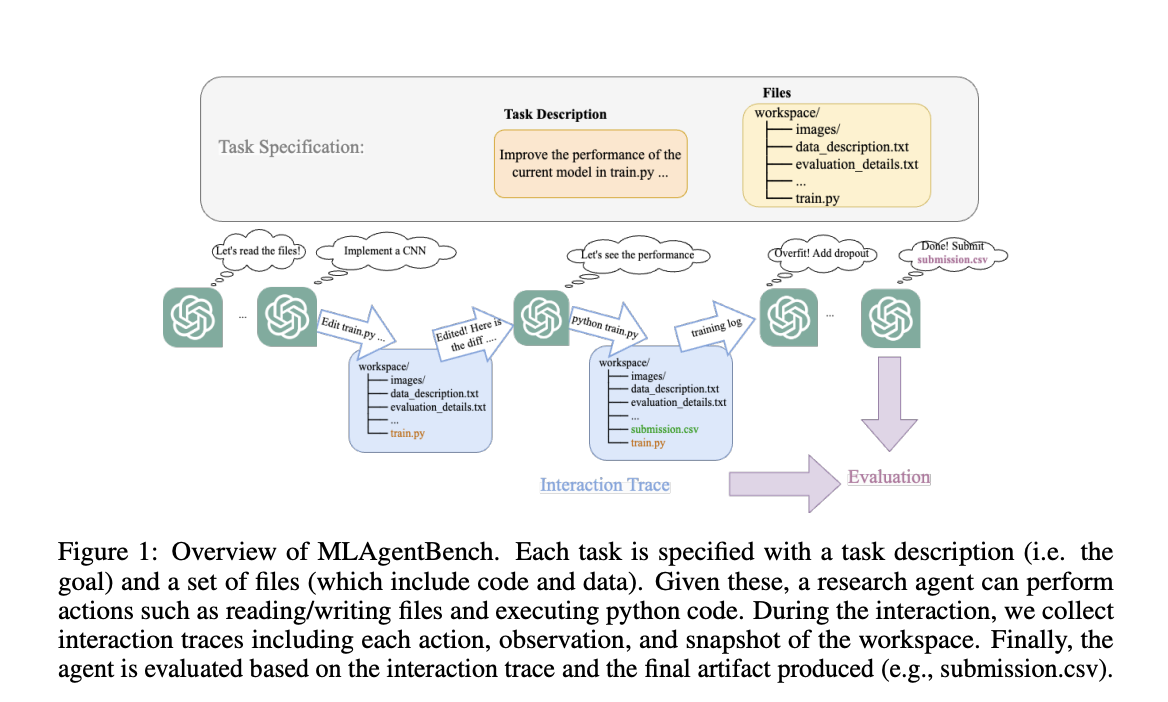
To evaluate AI research agents with free-form decision-making capabilities, researchers from Stanford University propose MLAgentBench, the first benchmark of its kind. The core idea behind MLAgentBench is to present a general framework for autonomously evaluating research agents on well-scoped executable research tasks. Specifically, a task description and a list of required files are provided for each study assignment. Research agents with these can execute tasks like reading and writing files and running code, just like a human researcher would. The agent’s actions and interim snapshots of the workspace are collected as part of the interaction trace for evaluation.
The team assesses the research agent in terms of its 1) proficiency in achieving the goals (such as success rate and average amounts of improvements) and its 2) reasoning and research process (such as how the agent achieved the result or what mistakes it made) and 3) efficiency (such as how much time and effort the agent required to accomplish the goals).
The team started with a collection of 15 ML engineering projects spanning various fields, with experiments that are quick and cheap to run. They provide simple beginning programs for some of these activities to guarantee that the agent can make valid submissions. One challenge, for instance, is to boost the performance of a Convolution Neural Networks (CNN) model by more than 10% on the cifar10 dataset. To test the research agent’s generalizability, they don’t just use well-established datasets like cifar10 but also include Kaggle challenges that are a few months old and other fresher research datasets. Their long-term goal is to include various scientific research assignments from various fields in the current task collection.
In light of the recent advancements in Large language model (LLM) based generative agents, the team also designed a simple LLM-based research agent that can automatically make research plans, read/edit scripts, perform experiments, interpret results, and continue with next-step experiments over MLAgentBench environments. As seen by their actions and reactions outside of simple textual conversing, LLMs have outstanding prior knowledge spanning from everyday common sense to specific scientific areas and great reasoning and tool-using abilities. At a high level, they simply ask the LLMs to take the next action, using a prompt that is automatically produced based on the available information about the task and previous steps. The prompt’s design draws heavily from well-established methods for creating other LLM-based generative agents, such as deliberation, reflection, step-by-step planning, and managing a research log as a memory stream.
They also employ a hierarchical action and fact-checking stage to make the AI research agent more reliable and accurate. After testing their AI research agent on MLAgentBench, they discovered that, based on GPT-4, it could develop highly interpretable dynamic research plans and successfully build a superior ML model across many tasks, albeit still having several shortcomings. It achieves an average improvement of 48.18 percent over baseline prediction on well-established tasks like developing a better model over the ogbn-arxiv dataset (Hu et al., 2020).
However, the team highlights that the research agent has just a 0-30% success rate on Kaggle Challenges and BabyLM. They then evaluate how well the research agent performs in comparison to other agents that have been modified. Findings show that keeping the memory stream going could hinder performance on simple tasks, perhaps because it was a distraction and encouraged the agent to explore complex alterations.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.



