Monocular depth estimation (MDE) plays an important role in various applications, including image and video editing, scene reconstruction, novel view synthesis, and robotic navigation. However, this task poses significant challenges due to the inherent scale distance ambiguity, making it ill-posed. Learning-based methods should utilize robust semantic knowledge to achieve accurate results and overcome this limitation. Recent progress has seen the adaptation of large diffusion models for MDE, treating depth prediction as a conditional image generation problem, but they suffer from slow inference speeds. The computational demands of repeatedly evaluating large neural networks during inference have become a major concern in the field.
Recently, various methods have been developed to address the challenges in MDE. One such method is Monocular depth estimation which predicts depth based on pixels. Another method is Metric depth estimation, which provides a more detailed representation but contains additional complexities due to camera focal length variations. Further, surface normal estimation has evolved from early learning-based approaches to complex deep learning methods. Recently, diffusion models have been applied to geometry estimation, with some methods producing multi-view depth and normal maps for single objects. Scene-level depth estimation approaches like VPD have used Stable Diffusion, but generalization remains a challenge for complex and real-world environments.
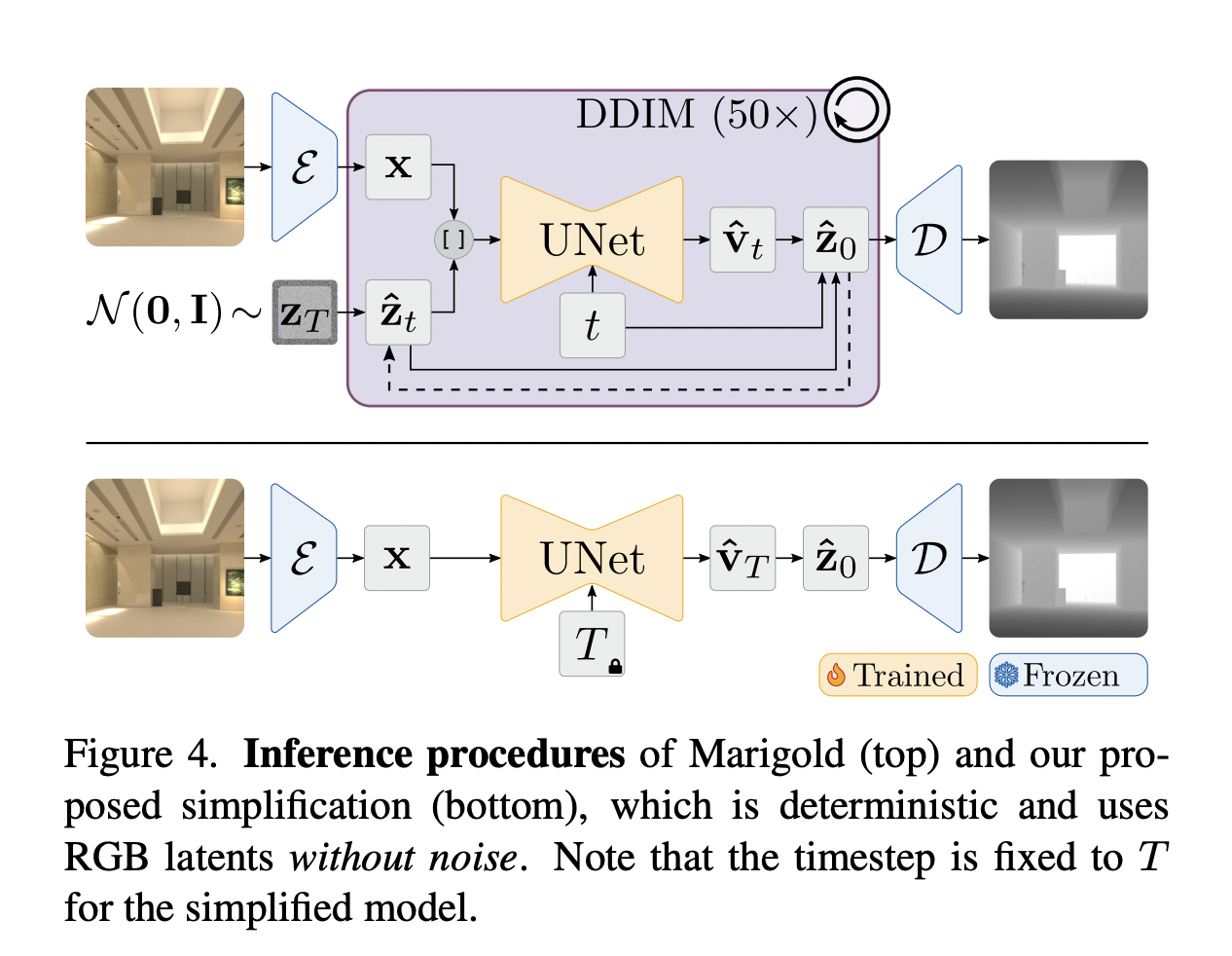
Researchers from RWTH Aachen University and Eindhoven University of Technology presented an innovative solution to the inefficiency of diffusion-based MDE. They developed a fixed model by taking an older unnoticed flaw in the inference pipeline, where the fixed model performs comparably to the best-reported configurations while being 200 times faster. An end-to-end fine-tuning is implemented with task-specific losses on top of their single-step model to enhance performance. This method results in a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. Moreover, this fine-tuning protocol works directly on Stable Diffusion, achieving comparable performance to state-of-the-art models.
The proposed method utilizes two synthetic datasets for training: Hypersim for photorealistic indoor scenes and Virtual KITTI 2 for driving scenarios to provide high-quality annotations. For evaluation, a diverse set of benchmarks, including NYUv2 and ScanNet for indoor environments, ETH3D and DIODE for mixed indoor-outdoor scenes, and KITTI for outdoor driving scenarios, are utilized. The implementation is built on the official Marigold checkpoint for depth estimation, while a similar setup is used for normal estimation, encoding normal maps as 3D vectors in color channels. The team follows Marigold’s hyperparameters, training all models for 20,000 iterations using the AdamW optimizer.
AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI AI
The results demonstrate that Marigold’s multi-step denoising process is not working as expected, with performance declining as the denoising steps increase. The fixed DDIM scheduler demonstrated superior performance across all step counts. Comparisons between vanilla Marigold, its Latent Consistency Model variant, and the researchers’ single-step models show that the fixed DDIM scheduler achieves comparable or better results in a single step without ensembling. Moreover, Marigold’s end-to-end fine-tuning outperforms all previous configurations in a single step without ensembling. Surprisingly, directly fine-tuning Stable Diffusion yields similar results to the Marigold-pretrained model.
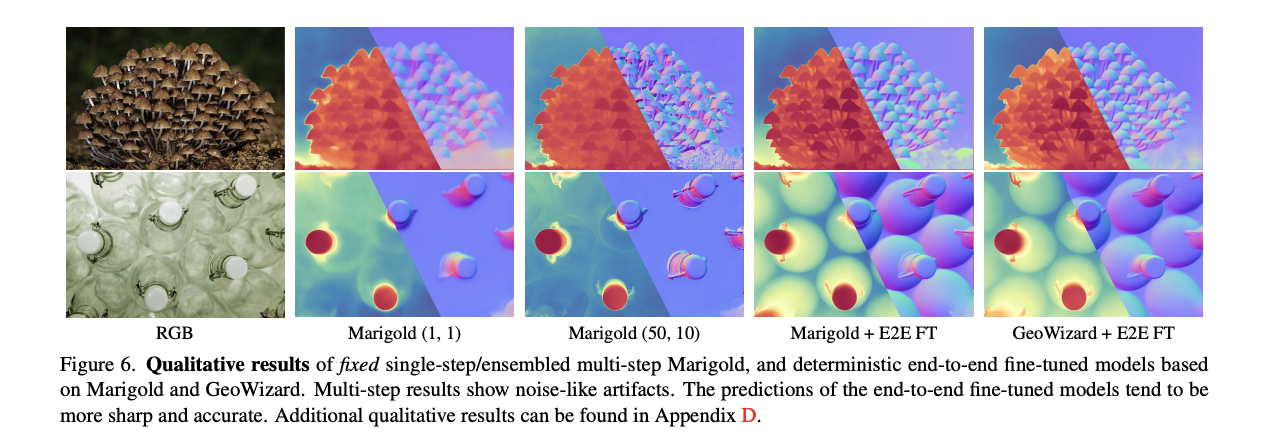
In summary, researchers introduced a solution to the inefficiency of diffusion-based MDE, revealing a critical flaw in the DDIM scheduler implementation. It challenges previous conclusions in diffusion-based monocular depth and normal estimation. Researchers showed that the simple end-to-end fine-tuning outperforms more complex training pipelines and architectures without losing support of the hypothesis that diffusion pretraining provides excellent priors for geometric tasks. The resulting models enable accurate single-step inference and make it possible to use large-scale data and advanced self-training methods. These findings lay the foundation for future advancements in diffusion models, making reliable priors and improved performance in geometry estimation.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.