In the field of Artificial Intelligence, open, generative models stand out as a cornerstone for progress. These models are vital for advancing research and fostering creativity by allowing fine-tuning and serving as benchmarks for new innovations. However, a significant challenge persists as many state-of-the-art text-to-audio models remain proprietary, limiting their accessibility for researchers.
Recently, a team of researchers from Stability AI has introduced a new open-weight text-to-audio model that is trained exclusively on Creative Commons data. This paradigm is intended to guarantee openness and moral data use while offering the AI community a potent tool. Its key features are as follows:
- This new model has open weights, in contrast to numerous proprietary models. This enables researchers and developers to examine, alter, and expand upon the model because its design and parameters are made available to the general public.
- Only audio files with Creative Commons licenses have been used to train the model. This decision guarantees the training materials’ ethical and legal soundness. The developers have encouraged openness in data methods and steered clear of possible copyright issues by using data that is available under Creative Commons.
The architecture of the new model is intended to provide accessible, high-quality audio synthesis, which is as follows:
- The model makes use of a sophisticated architecture that provides remarkable fidelity in text-to-audio generation. At a sampling rate of 44.1kHz, it can generate high-quality stereo sound, guaranteeing that the resulting audio satisfies strict requirements for clarity and realism.
- A variety of audio files with Creative Commons licenses have been used in the instruction process. This method guarantees that the model can produce realistic and varied audio outputs while also assisting it in learning from a wide variety of soundscapes.
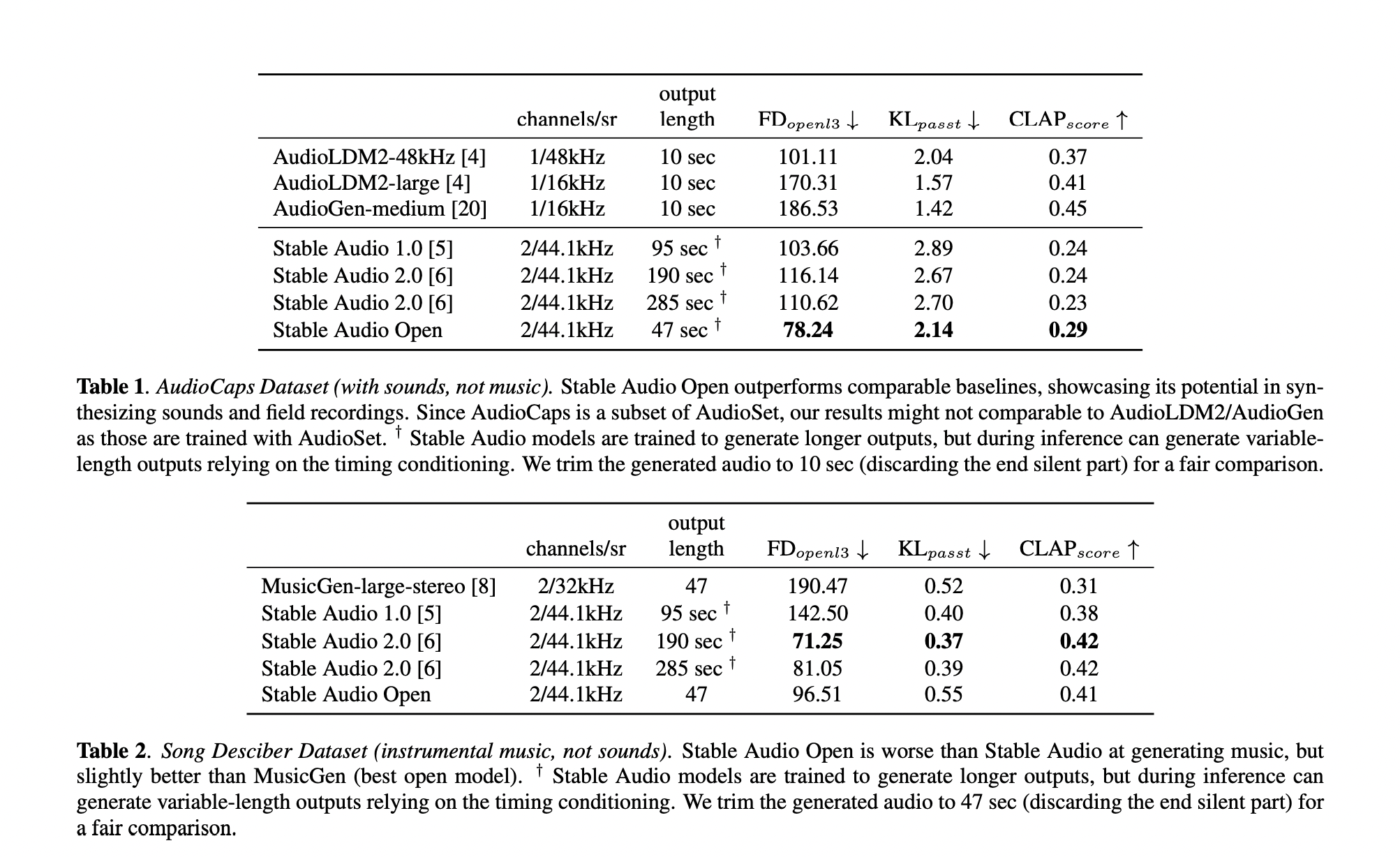
To make sure the new model matches or exceeds the standards set by the previous models, its performance has been thoroughly assessed. Measuring the realism of the generated audio, FDopenl3 is one of the primary assessment metrics employed. This metric’s findings showcased the model’s capacity to generate high-quality audio by showing that it performs on par with the industry’s top models. To evaluate the model’s capabilities and pinpoint areas for development, its performance has been compared to that of other well-performing models. This comparative study attests to the new model’s superior quality and usability.
In conclusion, the development of generative audio technology has advanced significantly with the release of this open-weight text-to-audio model. The concept solves many of the existing problems in the industry by emphasizing openness, ethical data utilization, and high-quality audio synthesis. It sets new standards for text-to-audio production and is a significant resource for scholars, artists, and developers.
news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news news
Check out the Paper, Model, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.