




The quest for efficient data processing techniques in machine learning and data science is paramount. These fields heavily rely on quickly and accurately sifting through massive datasets to derive actionable insights. The challenge lies in developing scalable methods that can accommodate the ever-increasing volume of data without a corresponding increase in processing time. The fundamental problem tackled by contemporary research is the inefficiency of existing data analysis methods. Traditional tools often need to catch up when tasked with processing large-scale data due to limitations in speed and adaptability. This inefficiency can significantly hinder progress, especially when real-time data analysis is crucial.
Existing work includes frameworks like Woodpecker, which focuses on extracting key concepts for hallucination diagnosis and mitigation in large language models. Models like AlpaGasus leverage fine-tuning high-quality data to enhance effectiveness and accuracy. Moreover, methodologies aim to improve factuality in outputs using similar fine-tuning techniques. These efforts collectively address critical issues in reliability and control, setting the groundwork for further advancements in the field.
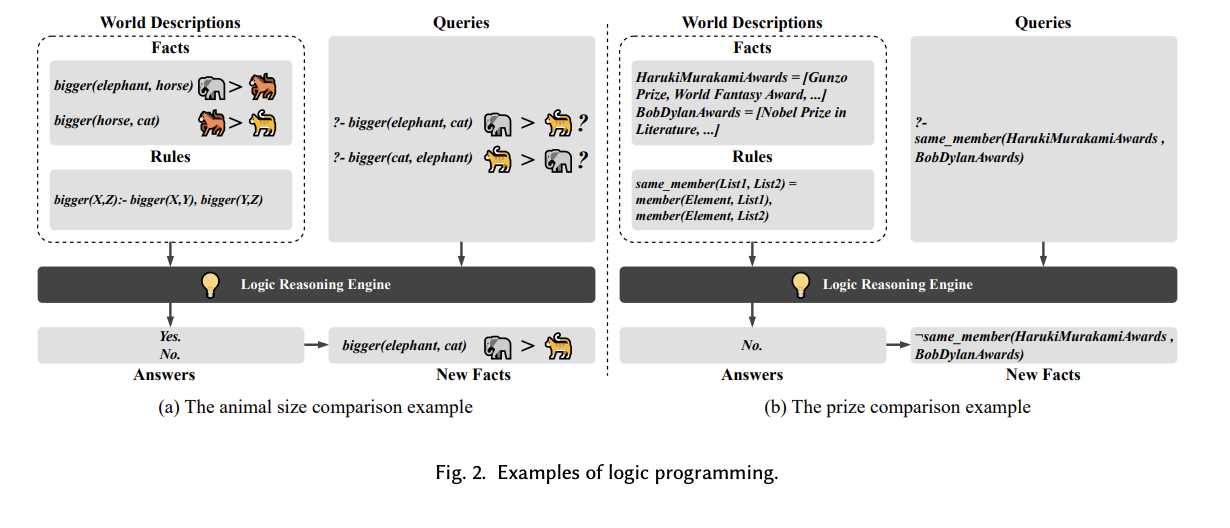
Researchers from Huazhong University of Science and Technology, the University of New South Wales, and Nanyang Technological University have introduced HalluVault. This novel framework employs logic programming and metamorphic testing to detect Fact-Conflicting Hallucinations (FCH) in Large Language Models (LLMs). This method stands out by automating the update and validation of benchmark datasets, which traditionally rely on manual curation. By integrating logic reasoning and semantic-aware oracles, HalluVault ensures that the LLM’s responses are not only factually accurate but also logically consistent, setting a new standard in evaluating LLMs.
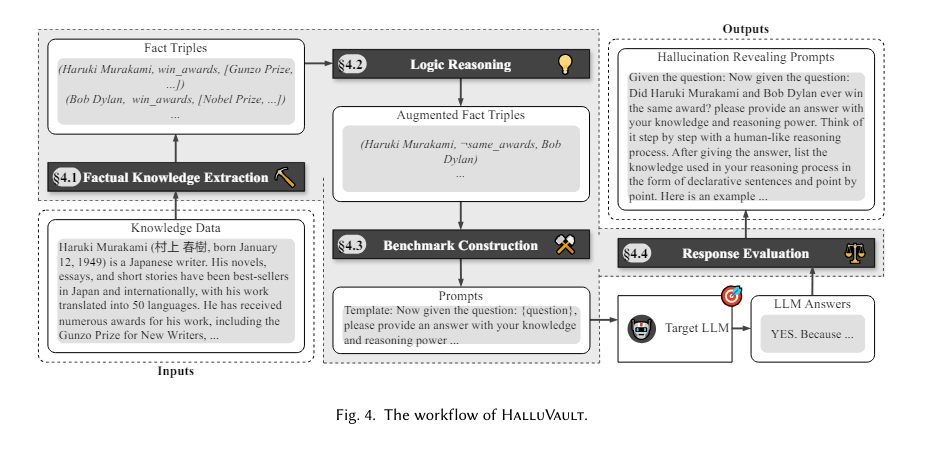
HalluVault’s methodology rigorously constructs a factual knowledge base primarily from Wikipedia data. The framework applies five unique logic reasoning rules to this base, creating a diversified and enriched dataset for testing. Test case-oracle pairs generated from this dataset serve as benchmarks for evaluating the consistency and accuracy of LLM responses. Two semantic-aware testing oracles are integral to the framework, assessing the semantic structure and logical consistency between the LLM outputs and the established truths. This systematic approach ensures that LLMs are evaluated under stringent conditions that mimic real-world data processing challenges, effectively measuring their reliability and factual accuracy.
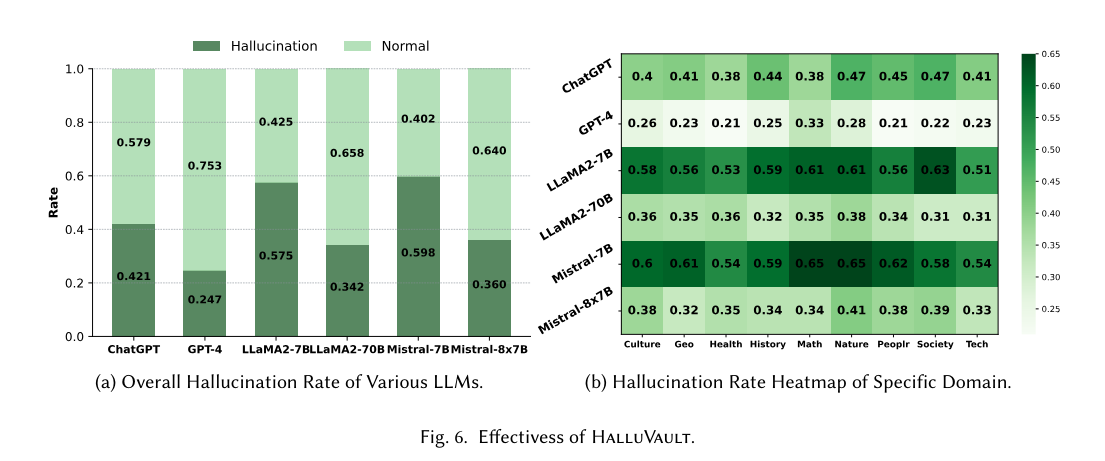
The evaluation of HalluVault revealed significant improvements in detecting factual inaccuracies in LLM responses. Through systematic testing, the framework reduced the rate of hallucinations by up to 40% compared to previous benchmarks. In trials, LLMs using HalluVault’s methodology demonstrated a 70% increase in accuracy when responding to complex queries across varied knowledge domains. Furthermore, the semantic-aware oracles successfully identified logical inconsistencies in 95% of test cases, ensuring robust validation of LLM outputs against the enhanced factual dataset. These results validate HalluVault’s effectiveness in enhancing the factual reliability of LLMs.
To conclude, HalluVault introduces a robust framework for enhancing the factual accuracy of LLMs through logic programming and metamorphic testing. The framework ensures that LLM outputs are factually and logically consistent by automating the creation and updating of benchmarks with enriched data sources like Wikipedia and employing semantic-aware testing oracles. The significant reduction in hallucination rates and improved accuracy in complex queries underscore the framework’s effectiveness, marking a substantial advancement in the reliability of LLMs for practical applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.



