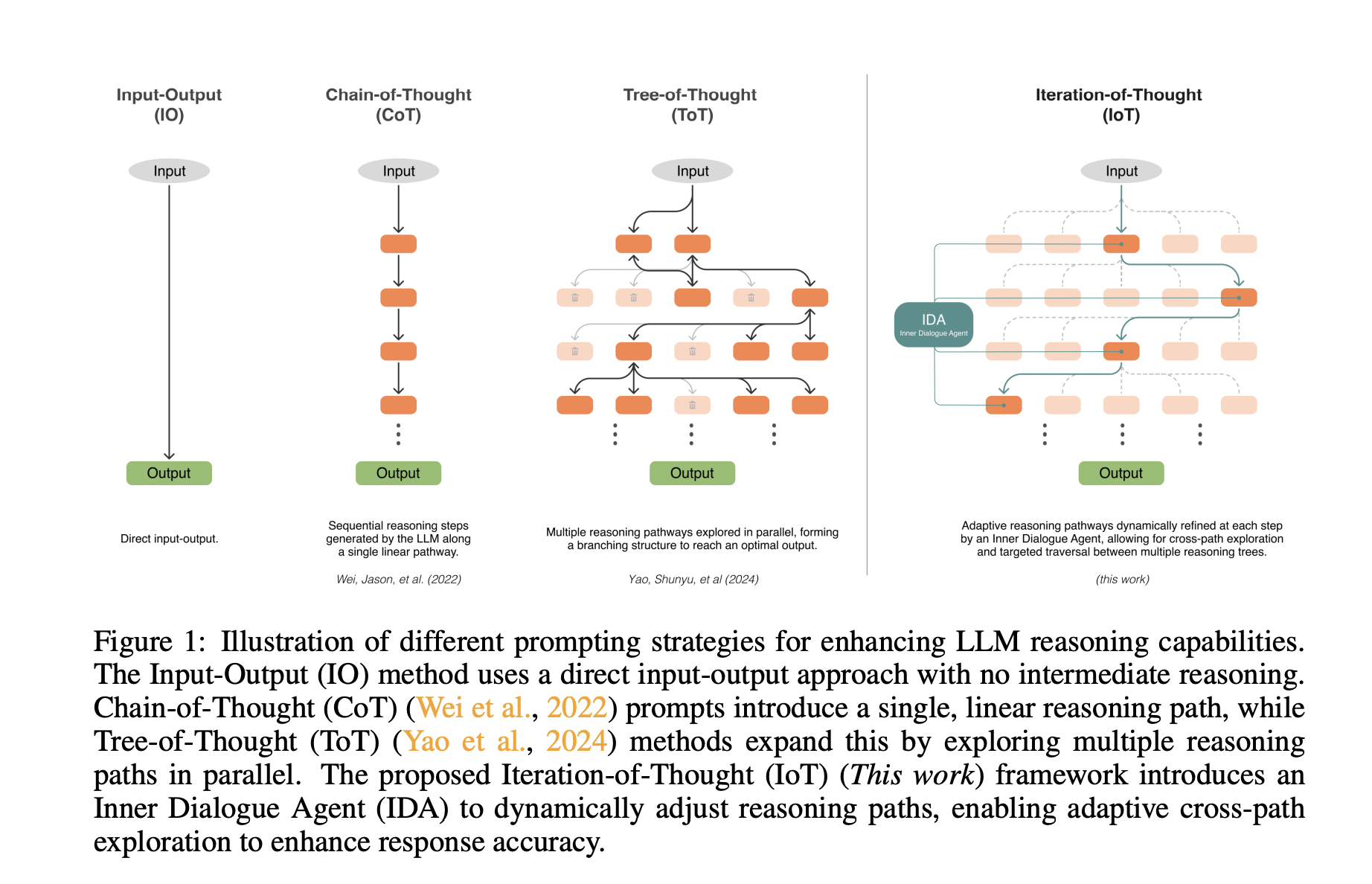
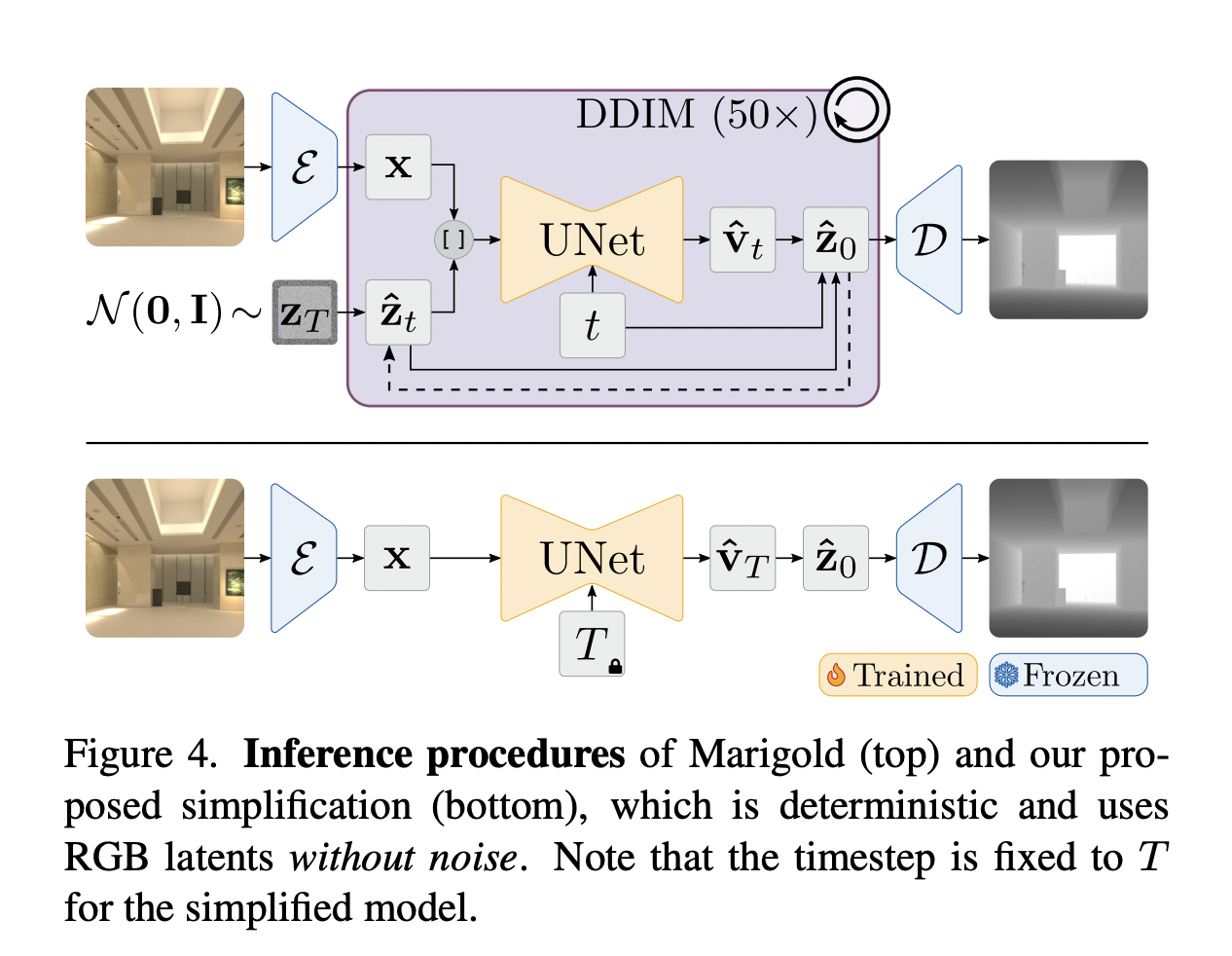
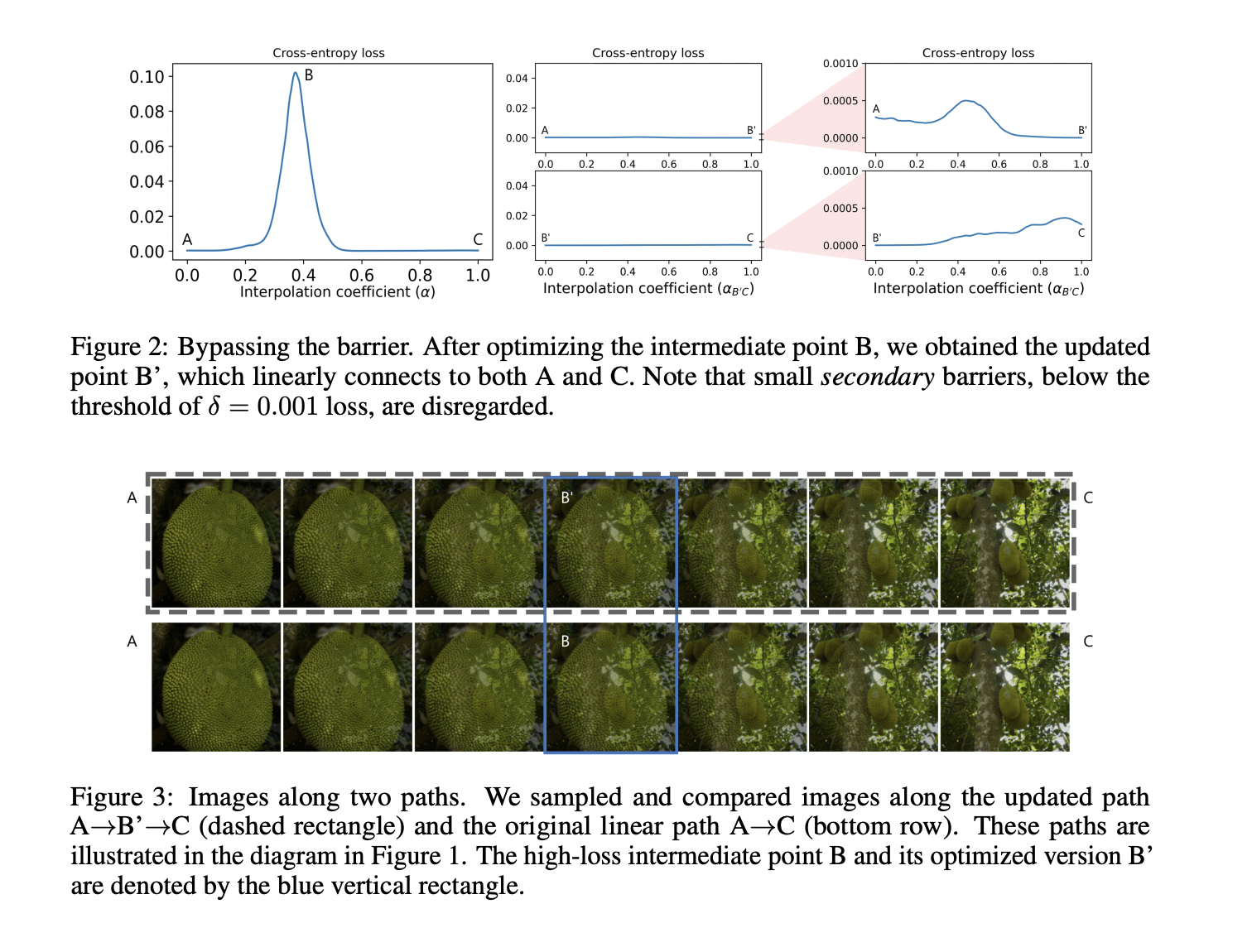
Tips for Effective Feature Selection in Machine Learning
Image by Author | Created on Canva
When training a machine learning model, you may sometimes work with datasets with a large number of features. However, only a small subset of these features will actually be important for the model to make predictions. Which is why you need feature selection to identify these helpful features.
This article covers useful tips for feature selection. We’ll not look at feature selection techniques in depth. But we’ll cover simple yet effective tips to understand the most relevant features in your dataset. We’ll not be working with any specific dataset. But you can try them out on a sample dataset of choice.
Let’s get started.
1. Understand the Data
You’re probably tired of reading this tip. But there’s no better way to approach any problem than to understand the problem you’re trying to solve and the data you’re working with.
So understanding your data is the first and most important step in feature selection. This involves exploring the dataset to better understand the distribution of variables, understanding the relationships between features, identifying potential anomalies and relevant features.
Key tasks in exploring data include checking for missing values, assessing data types, and generating summary statistics for numerical features.
This code snippet loads the dataset, provides a summary of data types and non-null values, generates basic descriptive statistics for numerical columns, and checks for missing values.
|
import pandas as pd # Load your dataset df = pd.read_csv(‘your_dataset.csv’) # Get an overview of the dataset print(df.info()) # Generate summary statistics for numerical features print(df.describe()) # Check for missing values in each column print(df.isnull().sum()) |
These steps help you understand more about the features in your data and potential data quality issues which need addressing before proceeding with feature selection.
2. Remove Irrelevant Features
Your dataset may have a large number of features. But not all of them will contribute to the predictive power of your model.
Such irrelevant features can add noise and increase model complexity without making it much effective. It’s essential to remove such features before training your model. And this should be straightforward if you have understood and explored the dataset in detail.
For example, you can drop a subset of irrelevant features like so:
|
# Assuming ‘feature1’, ‘feature2’, and ‘feature3’ are irrelevant features df = df.drop(columns=[‘feature1’, ‘feature2’, ‘feature3’]) |
In your code, replace ‘feature1’, ‘feature2’, and ‘feature3’ with the actual names of the irrelevant features you want to drop.
This step simplifies the dataset by removing unnecessary information, which can improve both model performance and interpretability.
3. Use Correlation Matrix to Identify Redundant Features
Sometimes you’ll have features that are highly correlated. A correlation matrix shows the correlation coefficients between pairs of features.
Highly correlated features can often be redundant, providing similar information to the model. In such cases, you can remove one of the correlated features can help.
Here’s the code to identify highly correlated pairs of features on the dataset:
|
import seaborn as sns import matplotlib.pyplot as plt # Compute the correlation matrix corr_matrix = df.corr() # Plot the heatmap of the correlation matrix sns.heatmap(corr_matrix, annot=True, cmap=‘coolwarm’) plt.show() # Identify highly correlated pairs threshold = 0.8 corr_pairs = corr_matrix.abs().unstack().sort_values(kind=“quicksort”, ascending=False) high_corr = [(a, b) for a, b in corr_pairs.index if a != b and corr_pairs[(a, b)] > threshold] |
Essentially, the above code aims to identify pairs of features with high correlation—those with an absolute correlation value greater than 0.8—excluding self-correlations. These highly correlated feature pairs are stored in a list for further analysis. You can then review and select features you wish to retain for the next steps.
4. Use Statistical Tests
You can use statistical tests to help you determine the importance of features relative to the target variable. And to do so, you can use functionality from scikit-learn’s feature_selection module.
The following snippet uses the chi-square test to evaluate the importance of each feature relative to the target variable. And the SelectKBest method is used to select the top features with the highest scores.
|
from sklearn.feature_selection import chi2, SelectKBest # Assume target variable is categorical X = df.drop(columns=[‘target’]) y = df[‘target’] # Apply chi-square test chi_selector = SelectKBest(chi2, k=10) X_kbest = chi_selector.fit_transform(X, y) # Display selected features selected_features = X.columns[chi_selector.get_support(indices=True)] print(selected_features) |
Doing so reduces the feature set to the most relevant variables, which can significantly improve model performance.
5. Use Recursive Feature Elimination (RFE)
Recursive Feature Elimination (RFE) is a feature selection technique that recursively removes the least important features and builds the model with the remaining features. This continues until the specified number of features is reached.
Here’s how you can use RFE to find the five most relevant features when building a logistic regression model.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split # Say ‘X’ is the feature matrix and ‘y’ is the target # Split into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=25) # Create a logistic regression model model = LogisticRegression() # Apply RFE on the training set to select the top 5 features rfe = RFE(model, n_features_to_select=5) X_train_rfe = rfe.fit_transform(X_train, y_train) X_test_rfe = rfe.transform(X_test) # Display selected features selected_features = X.columns[rfe.support_] print(selected_features) |
You can, therefore, use RFE to select the most important features by recursively removing the least important ones.
Wrapping Up
Effective feature selection is important in building robust machine learning models. To recap: you should understand your data, remove irrelevant features, identify redundant features using correlation, apply statistical tests, and use Recursive Feature Elimination (RFE) as needed to your model’s performance.
Happy feature selection! And if you’re looking for tips on feature engineering, read Tips for Effective Feature Engineering in Machine Learning.
About Bala Priya C
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she’s working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.