




In recent years, there have been exceptional advancements in Artificial Intelligence, with many new advanced models being introduced, especially in NLP and Computer Vision. CLIP is a neural network developed by OpenAI trained on a massive dataset of text and image pairs. It has helped advance numerous computer vision research and has supported modern recognition systems and generative models. Researchers believe that CLIP owes its effectiveness to the data it was trained on, and they believe that uncovering the data curation process would allow them to create even more effective algorithms.
In this research paper, the researchers have tried to make the data curation approach of CLIP available to the public and have introduced Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes unorganized data and metadata derived from CLIP’s concepts, creates a balanced subset, and yields a balanced subset over the metadata distribution. It outperforms CLIP’s data on multiple benchmarks when applied to the CommonCrawl dataset with 400M image-text pairs.
The authors of this paper have applied the following principles to achieve their goal:
- The researchers have first curated a new dataset of 400M image-text pairs collected from various internet sources.
- Using substring matching, they align image-text pairs with metadata entries, which effectively associates unstructured texts with structured metadata.
- All texts associated with each metadata entry are then grouped into lists, creating a mapping from each entry to the corresponding texts.
- The associated list is then sub-sampled, ensuring a more balanced data distribution, making it more general-purpose for pre-training.
- To formalize the curation process, they introduce an algorithm that aims to improve scalability and reduce space complexity.
MetaCLIP curates data without using the images directly, but it still improves the alignment of visual content by controlling the quality and distribution of the text. The process of substring matching makes it more likely that the text will mention the entities in the image, which increases the chance of finding the corresponding visual content. Additionally, balancing favors long-tailed entries, which may have more diverse visual content than head entries.
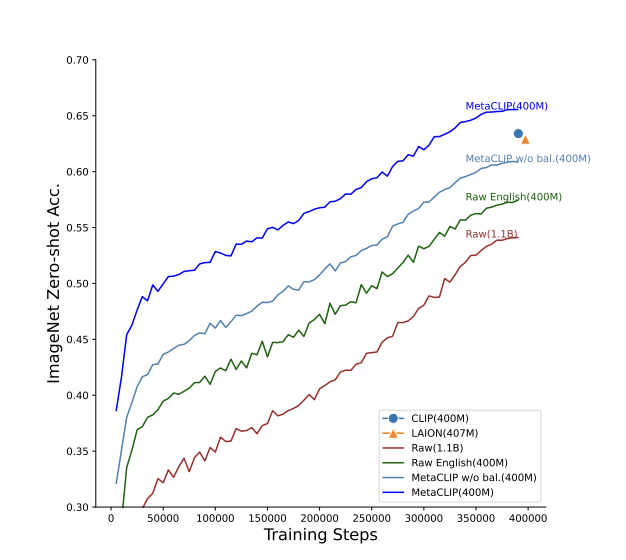
For experiments, the researchers used two pools of data – one to estimate a target of 400M image-text pairs and the other to scale the curation process. As mentioned earlier, MetaCLIP outperforms CLIP when applied to CommonCrawl with 400M data points. Additionally, MetaCLIP outperforms CLIP on zero-shot ImageNet classification using ViT models of various sizes.
MetaCLIP achieves 70.8% accuracy on zero-shot ImageNet classification using a ViT-B model, while CLIP achieves 68.3% accuracy. MetaCLIP also achieves 76.2% accuracy using a ViT-L model, while CLIP achieves 75.5% accuracy. Scaling the training data to 2.5B image-text pairs and using the same training budget and similar distribution further improves MetaCLIP’s accuracy to 79.2% for ViT-L and 80.5% for ViT-H. These are unprecedented results for zero-shot ImageNet classification.
In conclusion, in an attempt to understand the data curation process of OpenAI’s CLIP so that its high performance could be replicated, the authors of this paper have introduced MetaCLIP, which outperforms CLIP’s data on multiple benchmarks. MetaCLIP achieves this by using substring matching to align image-text pairs with metadata entries and sub-sampling the associated list to ensure a more balanced data distribution. This makes MetaCLIP a promising new approach for data curation and has the potential to enable the development of even more effective algorithms.
link|link|link|link|link|link|link|link|link|link|link|link|link|link|link|
link|link|link|link|link|link|link|link|link|link|link|link|link|link|link|
link|link|link|link|link|link|link|link|link|link|link|link|link|link|link|link|
link|link|link|link|link|link|link|link|link|link|link|link|link|link|link|link|link|link|link
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.



