





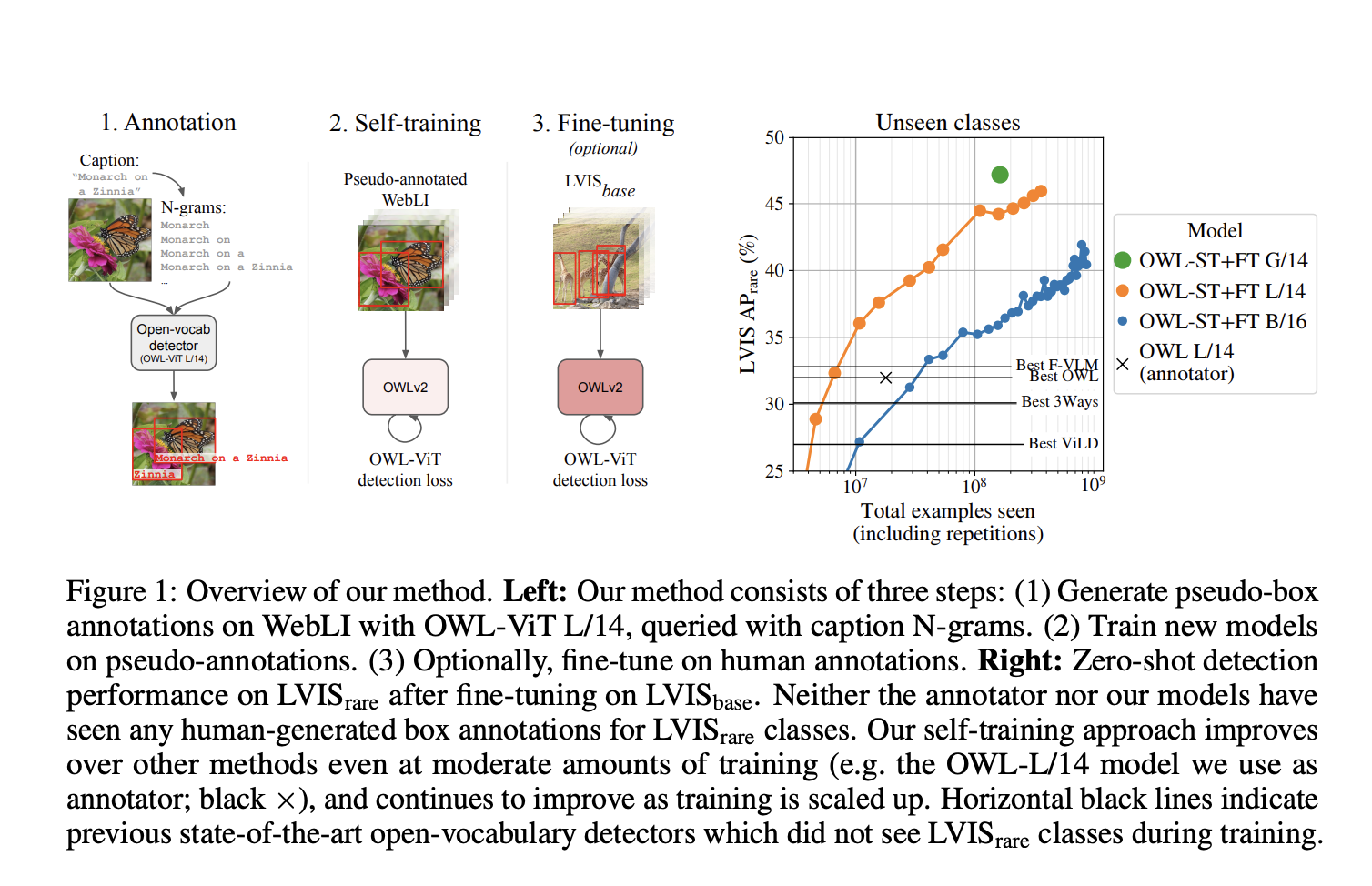
Open-vocabulary object detection is a critical aspect of various real-world computer vision tasks. However, the limited availability of detection training data and the fragility of pre-trained models often lead to subpar performance and scalability issues.
To tackle this challenge, the DeepMind research team introduces the OWLv2 model in their latest paper, “Scaling Open-Vocabulary Object Detection.” This optimized architecture improves training efficiency and incorporates the OWL-ST self-training recipe, substantially enhancing detection performance and achieving state-of-the-art results in the open-vocabulary detection task.
The primary objective of this work is to optimize the label space, annotation filtering, and training efficiency for the open-vocabulary detection self-training approach, ultimately achieving robust and scalable open-vocabulary performance with limited labeled data.
The proposed self-training approach consists of three key steps:
- The team employs an existing open-vocabulary detector to perform open box detection on WebLI, a large-scale dataset of web image-text pairs.
- They utilize OWL-ViT CLIP-L/14 to annotate all the WebLI images with bounding box pseudo annotations.
- They fine-tune the trained model using human-annotated detection data, further refining its performance.
Notably, the researchers employ a variant of the OWL-ViT architecture to train more effective detectors. This architecture leverages contrastively trained image-text models to initialize image and text encoders while the detection heads are randomly initialized.
During the training stage, the team employs the same losses and augments queries with “pseudo-negatives” from the OWL-ViT architecture, optimizing training efficiency to maximize the utilization of the available labeled images.
They also incorporate previously proposed practices for large-scale Transformer training to enhance training efficiency further. As a result, the OWLv2 model reduces training FLOPS by approximately 50% and accelerates training throughput by 2× compared to the original OWL-ViT model.
The team compares their proposed approach with previous state-of-the-art open-vocabulary detectors in their empirical study. The OWL-ST technique improves Average Precision (AP) on LVIS rare classes from 31.2% to 44.6%. Moreover, combining the OWL-ST recipe with the OWLv2 architecture achieves new state-of-the-art performance.
Overall, the OWL-ST recipe presented in this paper significantly improves detection performance by leveraging weak supervision from large-scale web data, enabling web-scale training for open-world localization. This approach addresses the limitations posed by the scarcity of labeled detection data and demonstrates the potential for achieving robust open-vocabulary object detection in a scalable manner.
Check Out the Paper. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools:
🚀 Check Out 100’s AI Tools in AI Tools Club
Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.



