




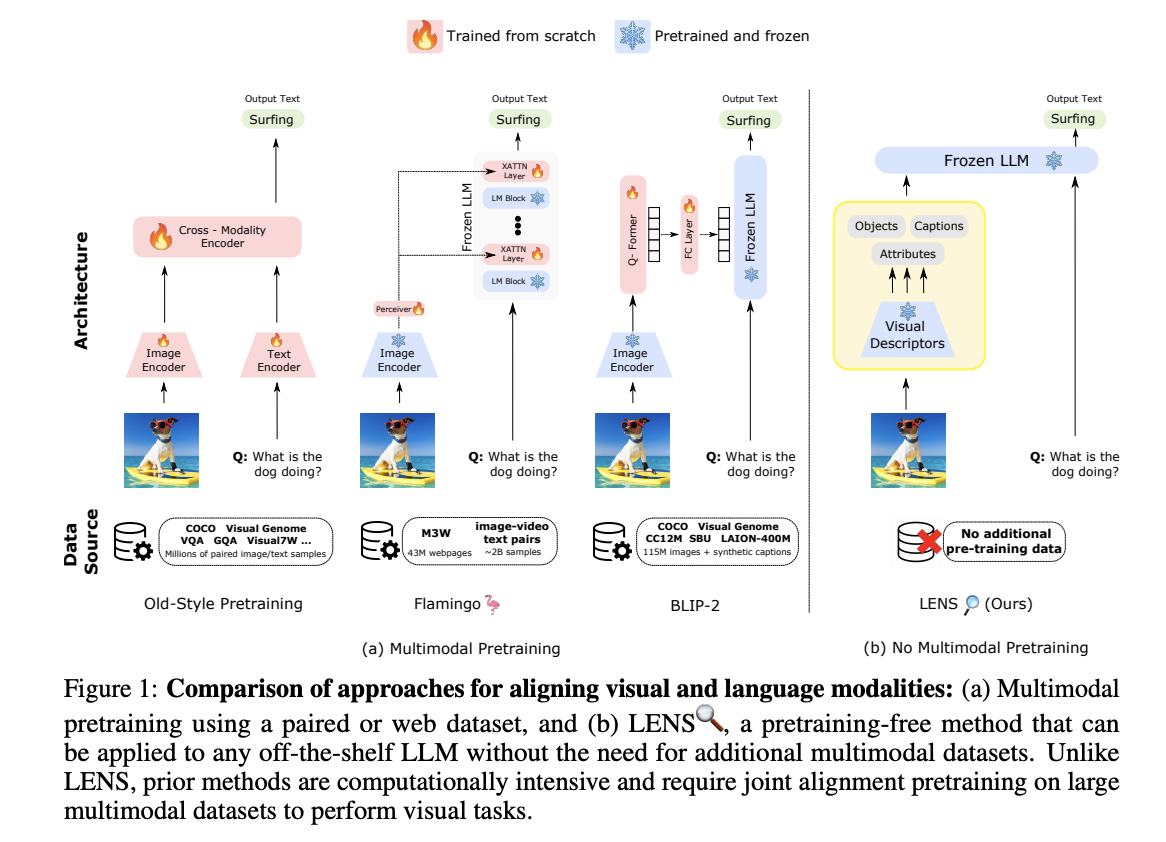
Large Language Models (LLMs) have transformed natural language understanding in recent years, demonstrating remarkable aptitudes in semantic comprehension, query resolution, and text production, particularly in zero-shot and few-shot environments. As seen in Fig. 1(a), several methods have been put forth for using LLMs on tasks involving vision. An optical encoder may be trained to represent each picture as a series of continuous embeddings, allowing the LLM to understand it. Another uses a contrastively trained frozen vision encoder while adding additional layers to the frozen LLM that are then learned from scratch.
Another method recommends training a lightweight transformer to align a frozen visual encoder (pre-trained contrastively) and a frozen LLM. Even if they have progressed in the abovementioned research, it is still difficult to justify the additional pretraining stage(s)’ computational cost. In addition, massive databases, including text, photos, and videos, are required to synchronize the visual and linguistic modalities with an existing LLM. Flamingo adds new cross-attention layers into an LLM pre-trained to add visual features.
The multimodal pretraining stage requires stunning 2 billion picture-text pairs and 43 million websites, which can take up to 15 days, even employing a pretrained image encoder and a pretrained frozen LLM. Instead, using a variety of “vision modules,” they can extract information from visual inputs and produce detailed textual representations (such as tags, attributes, actions, and relationships, among other things), which they can then feed directly to the LLM to avoid the need for additional multimodal pretraining, as shown in Fig. 1(b). Researchers from Contextual AI and Stanford University introduce LENS (Large Language Models ENnhanced to See) a modular strategy that uses an LLM as the “reasoning module” and functions across separate “vision modules.”
They first extract rich textual information in the LENS technique using pretrained vision modules, such as contrastive models and image-captioning models. The text is then sent to the LLM, enabling it to carry out tasks, including object recognition, vision, and language (V&L). LENS bridges the gap between the modalities at no expense by eliminating the necessity for additional multimodal pretraining stages or data. Incorporating LENS gives them a model that operates across domains out of the box without the need for additional cross-domain pretraining. Additionally, this integration enables us to immediately use the most recent developments in computer vision and natural language processing, maximizing the advantages associated with both disciplines.
They provide the following contributions:
• They present LENS, a modular method that handles computer vision challenges by using language models’ few-shot, in-context learning capabilities through natural language descriptions of visual inputs.
• LENS gives any off-the-shelf LLM the ability to see without further training or data.
• They use frozen LLMs to handle object recognition and visual reasoning tasks without additional vision-and-language alignment or multimodal data. Experimental results show that their approach achieves zero-shot performance that is competitive with or superior to end-to-end jointly pre-trained models like Kosmos and Flamingo. A partial implementation of their paper is available on GitHub.
Check Out the Paper, Demo, Github link, and Blog. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools:
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.



