




Artificial Intelligence is evolving with the introduction of Generative AI and Large Language Models (LLMs). Well-known models like GPT, BERT, PaLM, etc., are some great additions to the long list of LLMs that are transforming how humans and computers interact. In image generation, diffusion models have gained significant attention from researchers as these models capture the complex probability distribution of an image dataset and generate new samples that resemble the training data. 3D scene understanding is also evolving, enabling the development of geometry-free neural networks that can be trained on a large dataset of scenes to learn scene representations. These networks generalize well to unseen scenes and objects, render views from just a single or a few input images, and only need a few observations per scene for training.
By combining the capabilities of diffusion models and 3D scene representation learning models, a team of researchers from UC Berkeley, Google Research, and Google DeepMind has introduced DORSal (Diffusion for Object-centric Representations of Scenes et al.), which is an approach for the generation of novel perspectives in three-dimensional scenes by combining object representations with diffusion decoders. DORSal is geometry-free as it learns 3D scene structure purely from data without requiring any expensive volume rendering.
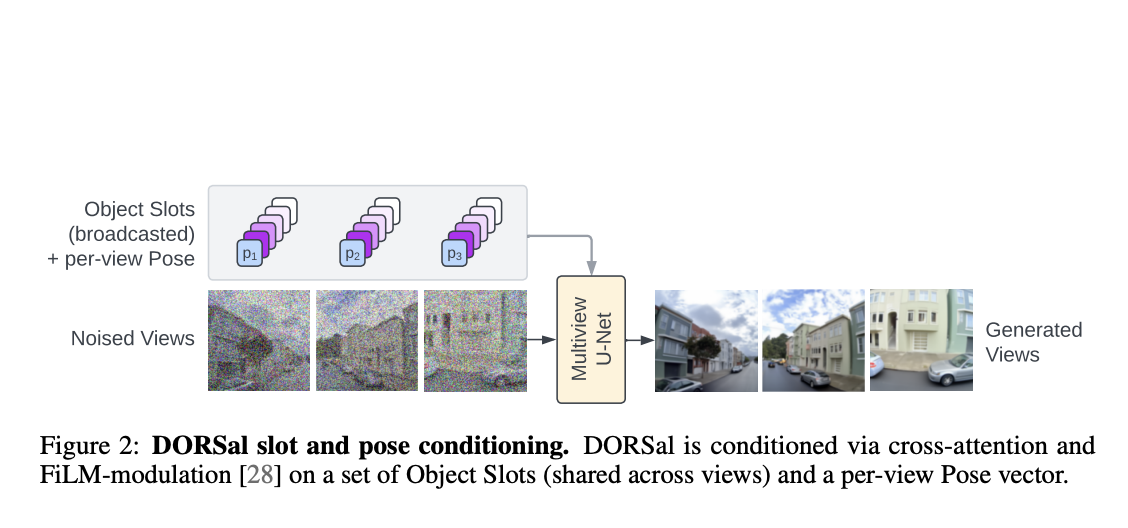
For the purpose of creating 3D scenes, DORSal utilizes a video diffusion architecture that was initially created for picture synthesis purposes. The main concept is to rely on object-centric slot-based representations of scenes to constrain the diffusion model. These depictions capture crucial details about the scene’s objects and their characteristics. DORSal facilitates the synthesis of high-fidelity innovative perspectives of 3D scenes by configuring the diffusion model on these object-centric representations. It also keeps the capability of object-level scene editing, enabling users to change and alter particular items in the scene.
The main contributions shared by the team are as follows –
- DORSal, an approach to 3D novel-view synthesis, uses the strengths of diffusion models and object-centric scene representations to improve the quality of rendered views.
- DORSal outperforms prior methods from the 3D scene understanding literature and is able to generate views that are significantly more precise, with a 5x-10x improvement in Fréchet Inception Distance (FID).
- In comparison to previous work on 3D Diffusion Models, DORSal shows superior performance in handling more complex scenes. Upon evaluating real-world Street View data, DORSal performs significantly better in terms of rendering quality.
- DORSal is capable of conditioning the diffusion model on a structured, object-based scene representation. By using this representation, DORSal learns to compose scenes using individual objects, which enables basic object-level scene editing during inference, allowing users to manipulate and modify specific objects within the scene.
In conclusion, the effectiveness of DORSal can be seen by the experiments conducted on both complex synthetic multi-object scenes and real-world, large-scale datasets like Google Street View. Its ability to successfully enable scalable neural rendering of 3D scenes with object-level editing makes it a promising approach for the future. Its improved rendering quality shows potential for advancing 3D scene understanding.
Check Out the Project Page and Paper. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools:
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.



