





Recent developments have seen a remarkable increase in the capability of large language models (LLMs), with generative pretrained transformer (GPT) models showing significant promise. The transition from GPT-3 to GPT-4, as well as the appearance of other LLMs like PaLM and LLaMA, demonstrated a considerable improvement in problem-solving and natural language understanding skills. Additionally, generative models are frequently used in a variety of sectors to generate data for different applications. When LLMs are used in applications that need a high level of accuracy and dependability, like the biological and healthcare areas, the problem of hallucination remains a significant barrier.
Unfortunately, there are no systematic techniques available to accurately detect hallucinations or gauge the output’s level of confidence. Particularly after using reinforcement learning with human input, the intrinsic confidence score from the generative LLMs is sometimes unavailable or not effectively calibrated with regard to the intended aim. Heuristic techniques are costly to compute and are subject to bias from the LLM itself, such as sampling an ensemble of LLM answers. There are two basic categories of methods for evaluating the degree of confidence in LLM replies. In the first, the LLM is prodded in a variety of ways to create many replies, which are then used to infer the answer’s dependability.
Self-consistency and chain-of-thought prompting are two examples. These techniques are less quantitative and susceptible to model-induced bias in the estimated confidence. There is no standardised way to measure this, but the prompting technique may have a significant impact on the quality of the outcomes. The second category of options turns to outside sources of data, such as hiring human reviewers to verify the answer or using huge amounts of labeled data to create assessment models. One of the primary obstacles to current supervised model training is the extensive manual annotation work that these techniques necessitate. In that regard, self-supervision offers a viable option since it can adaptably use data patterns and outside-the-box expertise.
Researchers from Microsoft in this study provide a flexible framework that uses Pareto optimum learning to mix data from both the LLM response and supervision sources. They were motivated by earlier efforts in programmatic supervision and the wealth of Pareto optimization research. The following intuitions guide their strategy. In order to prevent bias from an LLM judging itself, external sources of supervision that are independent of the LLM are required. Second, think of the LLM errors as noisy perturbations on the gold labels. When a model is fitted with both LLM noise and independent external noise, implicit label smoothing is actually performed, which enhances calibration power.
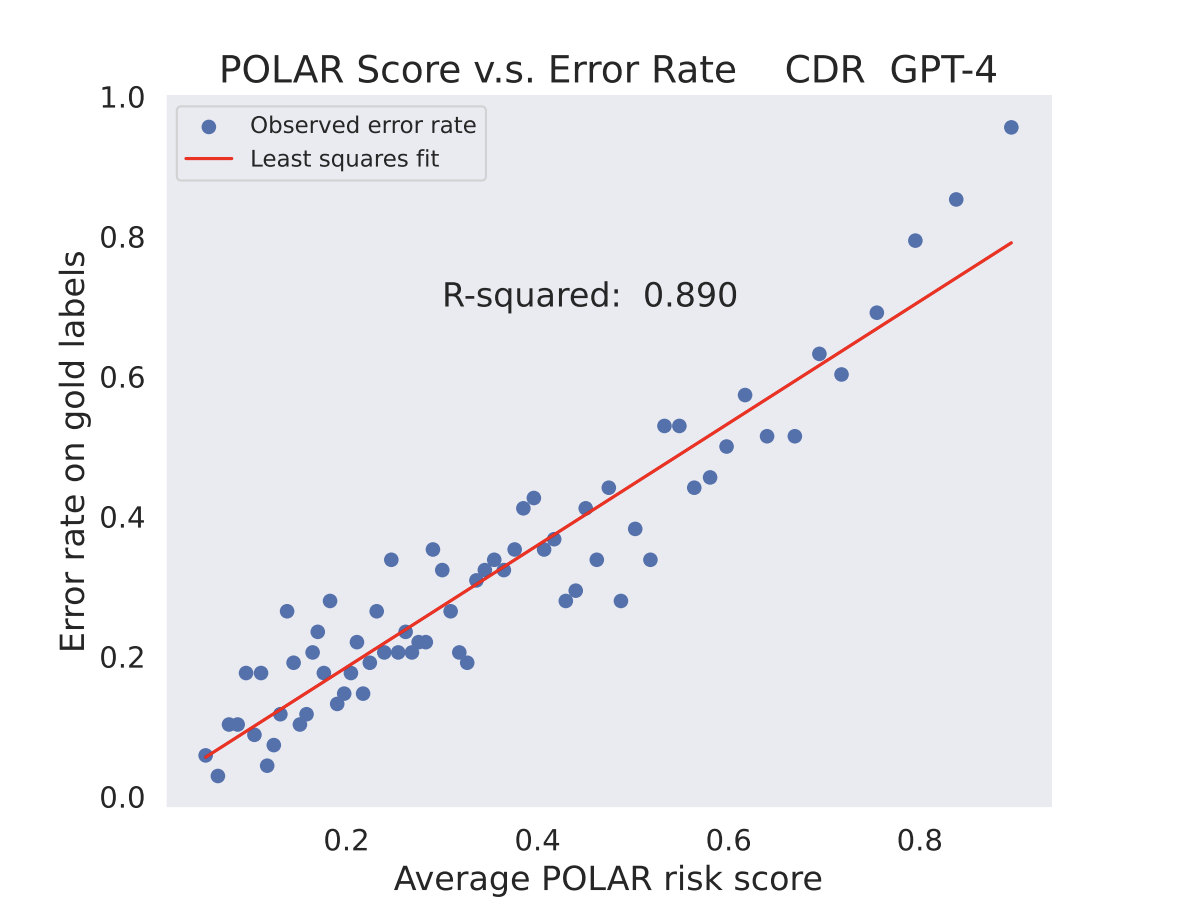
In that regard, Pareto optimum self-supervision provides a useful framework for integrating both qualities. Notably, the suggested method just needs unlabeled data, making it appropriate for fields where annotation is costly. Their unique approach to LLM calibration by Pareto optimum self-supervision is the paper’s key innovation. They suggest using the Pareto Optimum Learning assessed risk (POLAR) score to calculate the likelihood of LLM mistakes. They present experimental findings on four distinct NLP tasks and demonstrate that the suggested POLAR score is substantially linked with the LLM error rate assessed on gold labels. They show enhanced LLM performance for high-risk situations as determined by the POLAR score utilizing dynamic prompting strategies. Without utilizing any human-labeled training data, they demonstrate how their method can remove LLM mistakes and improve a GPT-4 baseline performance to exceed the most advanced supervised model.
Check Out the Paper. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, Twitter, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools:
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.



