





The 3D computer vision domain was flooded with NeRFs in recent years. They emerged as a groundbreaking technique and enabled the reconstruction and synthesis of novel views of a scene. NeRFs capture and model the underlying geometry and appearance information from a collection of multi-view images.
By leveraging neural networks, NeRFs offer a data-driven approach that surpasses traditional methods. The neural networks in NeRFs learn to represent the complex relationship between scene geometry, lighting, and view-dependent appearance, allowing for highly detailed and realistic scene reconstructions. The key advantage of NeRFs lies in their ability to generate photo-realistic images from any desired viewpoint within a scene, even in regions that were not captured by the original set of images.
The success of NeRFs has opened up new possibilities in computer graphics, virtual reality, and augmented reality, enabling the creation of immersive and interactive virtual environments that closely resemble real-world scenes. Therefore, there is a serious interest in the domain to advance NeRFs even further.
Some drawbacks of NeRFs limit their applicability in real-world scenarios. For example, editing neural fields is a significant challenge due to the implicit encoding of the shape and texture information within high-dimensional neural network features. While some methods tried to tackle this using explored editing techniques, they often require extensive user input and struggle to achieve precise and high-quality results.
The ability to edit NeRFs can open possibilities in real-world applications. However, so far, all the attempts were not good enough for them to solve the problems. Well, we have a new player in the game, and it’s named DreamEditor.
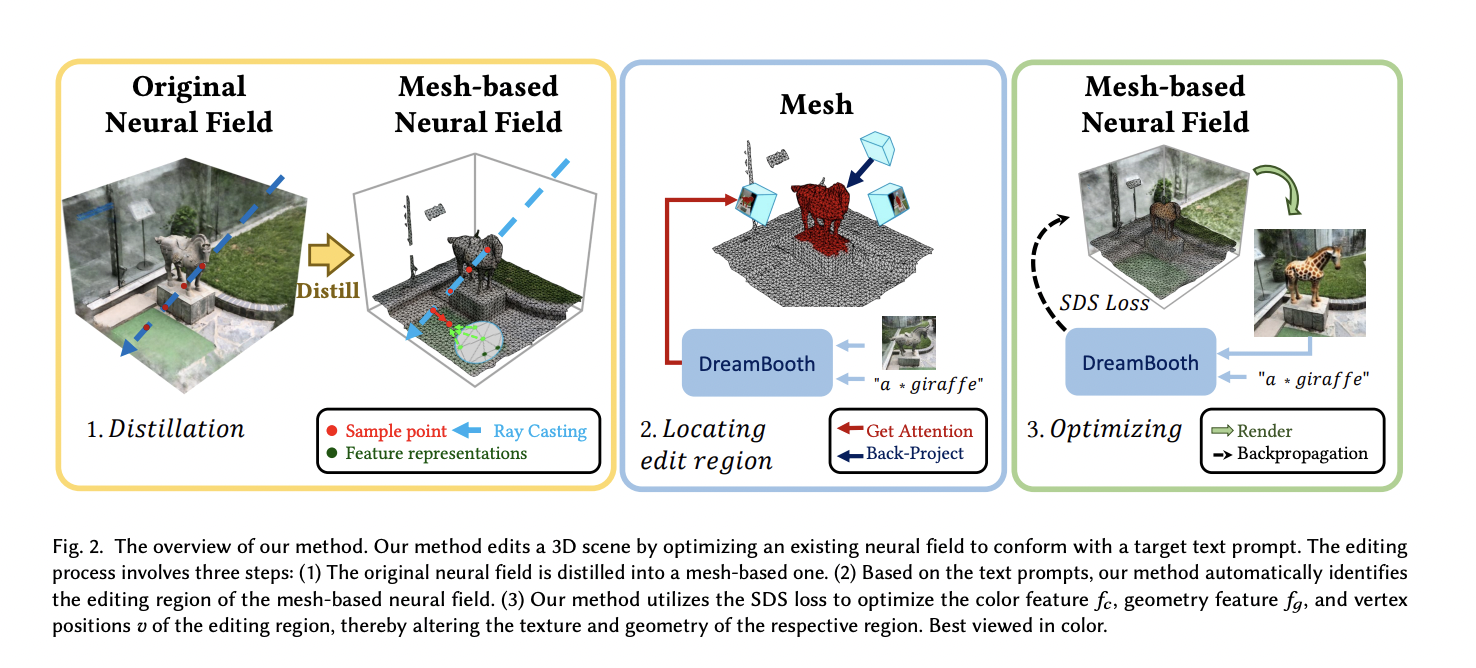
DreamEditor is a user-friendly framework that allows intuitive and convenient modification of neural fields using text prompts. By representing the scene with a mesh-based neural field and employing a stepwise editing framework, DreamEditor enables a wide range of editing effects, including re-texturing, object replacement, and object insertion.
The mesh representation facilitates precise local editing by converting 2D editing masks into 3D editing regions while also disentangling geometry and texture to prevent excessive deformation. The stepwise framework combines pre-trained diffusion models with score distillation sampling, allowing efficient and accurate editing based on simple text prompts.
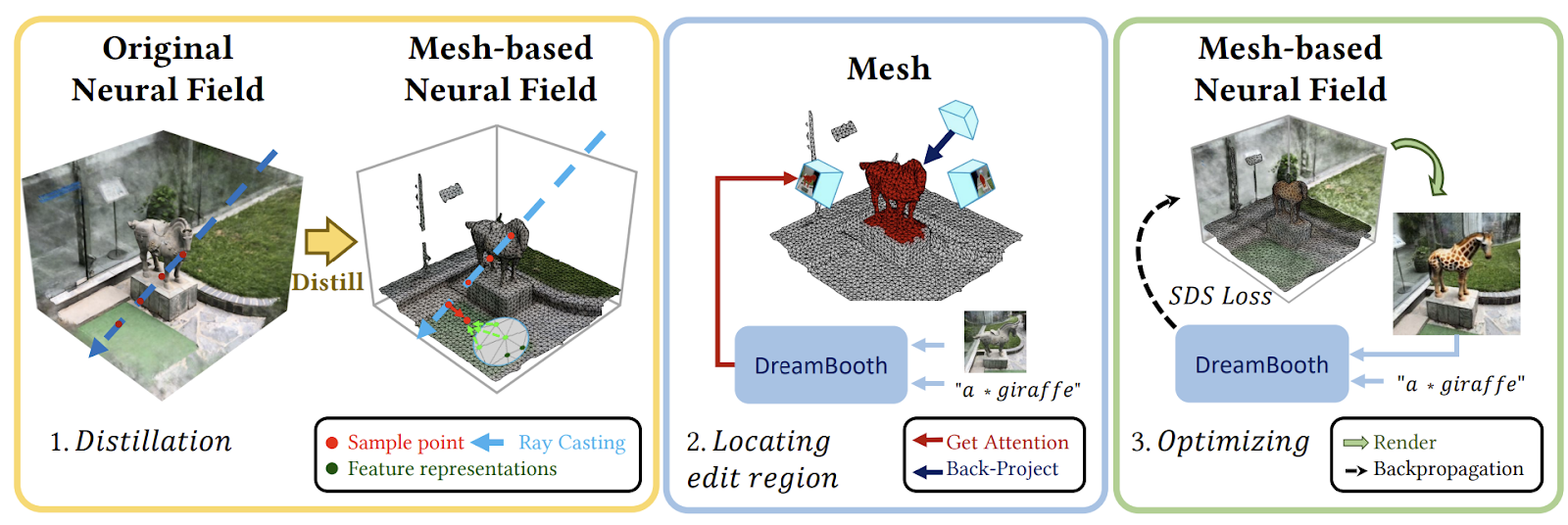
DreamEditor follows three key stages to facilitate intuitive and precise text-guided 3D scene editing. In the initial stage, the original neural radiance field is transformed into a mesh-based neural field. This mesh representation enables spatially-selective editing. After the conversion, it employs a customized Text-to-Image (T2I) model that is trained on the specific scene to capture the semantic relationships between keywords in the text prompts and the scene’s visual content. Finally, the edited modifications are applied to the target object within the neural field using the T2I diffusion mode.
DreamEditor can accurately and progressively edit the 3D scene while maintaining a high level of fidelity and realism. This stepwise approach, from mesh-based representation to precise localization and controlled editing through diffusion models, allows DreamEditor to achieve highly realistic editing results while minimizing unnecessary modifications in irrelevant regions.
Check out the Paper. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.



